第8章_字符串
1、字符串的不可变性
1.1 简介
String在Java中特别常用,而且我们经常要在代码中对字符串进行赋值和改变他的值,但是,为什么我们说字符串是不可变的呢?
首先,我们需要知道什么是不可变对象?
不可变对象是在完全创建后其内部状态保持不变的对象。这意味着,一旦对象被赋值给变量,我们既不能更新引用,也不能通过任何方式改变内部状态。
可是有人会有疑惑,String为什么不可变,我的代码中经常改变String的值啊,如下:
String s = "abcd";
s = s.concat("ef");
这样,操作,不就将原本的"abcd"的字符串改变成"abcdef"了么?
但是,虽然字符串内容看上去从"abcd"变成了"abcdef",但是实际上,我们得到的已经是一个新的字符串了。
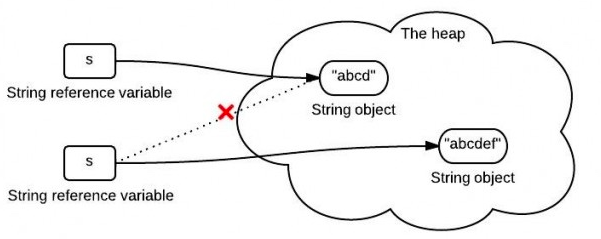
如上图,在堆中重新创建了一个"abcdef"字符串,和"abcd"并不是同一个对象。
所以,一旦一个string对象在内存(堆)中被创建出来,他就无法被修改。而且,String类的所有方法都没有改变字符串本身的值,都是返回了一个新的对象。
如果我们想要一个可修改的字符串,可以选择StringBuffer 或者 StringBuilder这两个代替String。
1.2 为什么String要设计成不可变
1.2.1 前言
在一次采访中James Gosling被问到什么时候应该使用不可变变量,他给出的回答是:
- I would use an immutable whenever I can.
其实,主要是从缓存、安全性、线程安全和性能等角度触发的。
Q:缓存、安全性、线程安全和性能?这有都是啥 A:你别急,听我一个一个给你讲就好了。
1.2.2 缓存
字符串是使用最广泛的数据结构。大量的字符串的创建是非常耗费资源的,所以,Java提供了对字符串的缓存功能,可以大大的节省堆空间。
JVM中专门开辟了一部分空间来存储Java字符串,那就是字符串池。
通过字符串池,两个内容相同的字符串变量,可以从池中指向同一个字符串对象,从而节省了关键的内存资源。
String s = "abcd";
String s2 = s;
对于这个例子,s和s2都表示"abcd",所以他们会指向字符串池中的同一个字符串对象:
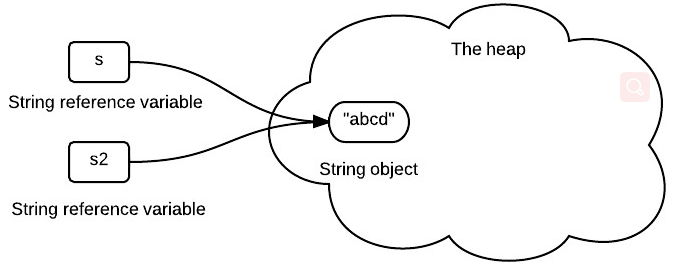
但是,之所以可以这么做,主要是因为字符串的不变性。试想一下,如果字符串是可变的,我们一旦修改了s的内容,那必然导致s2的内容也被动的改变了,这显然不是我们想看到的。
1.2.3 安全性
字符串在Java应用程序中广泛用于存储敏感信息,如用户名、密码、连接url、网络连接等。JVM类加载器在加载类的时也广泛地使用它。
因此,保护String类对于提升整个应用程序的安全性至关重要。
当我们在程序中传递一个字符串的时候,如果这个字符串的内容是不可变的,那么我们就可以相信这个字符串中的内容。
但是,如果是可变的,那么这个字符串内容就可能随时都被修改。那么这个字符串内容就完全不可信了。这样整个系统就没有安全性可言了。
1.2.4 线程安全
不可变会自动使字符串成为线程安全的,因为当从多个线程访问它们时,它们不会被更改。
因此,一般来说,不可变对象可以在同时运行的多个线程之间共享。它们也是线程安全的,因为如果线程更改了值,那么将在字符串池中创建一个新的字符串,而不是修改相同的值。因此,字符串对于多线程来说是安全的。
1.2.5 hashcode缓存
由于字符串对象被广泛地用作数据结构,它们也被广泛地用于哈希实现,如HashMap、HashTable、HashSet等。在对这些散列实现进行操作时,经常调用hashCode()方法。
不可变性保证了字符串的值不会改变。因此,hashCode()方法在String类中被重写,以方便缓存,这样在第一次hashCode()调用期间计算和缓存散列,并从那时起返回相同的值。
在String类中,有以下代码:
private int hash; //this is used to cache hash code
1.2.6 性能
前面提到了的字符串池、hashcode缓存等,都是提升性能的提现。
因为字符串不可变,所以可以用字符串池缓存,可以大大节省堆内存。而且还可以提前对hashcode进行缓存,更加高效。
由于字符串是应用最广泛的数据结构,提高字符串的性能对提高整个应用程序的总体性能有相当大的影响。
1.3 总结
字符串是不可变的,因此它们的引用可以被视为普通变量,可以在方法之间和线程之间传递它们,而不必担心它所指向的实际字符串对象是否会改变;
我们还了解了促使Java语言设计人员将该类设置为不可变类的其他原因。主要考虑的是缓存、安全性、线程安全和性能等方面。
2、JDK 6和JDK7中substring的原理及区别
substring(int beginIndex, int endIndex)方法在不同版本的JDK中的实现是不同的。了解他们的区别可以帮助你更好的使用他。为简单起见,后文中用substring()代表substring(int beginIndex, int endIndex)方法。
2.1 substring() 的作用
substring(int beginIndex, int endIndex)方法截取字符串并返回其[beginIndex,endIndex-1]范围内的内容。
String x = "abcdef";
x = x.substring(1,3);
System.out.println(x);
输出内容:bc
2.2 调用substring()时发生了什么?
你可能知道,因为x是不可变的,当使用x.substring(1,3)对x赋值的时候,它会指向一个全新的字符串:
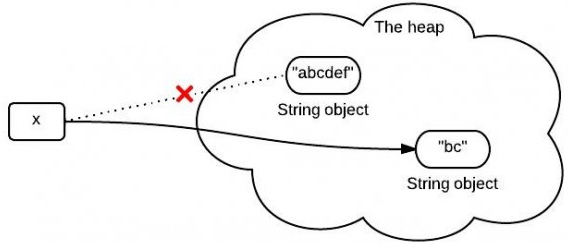
然而,这个图不是完全正确的表示堆中发生的事情。因为在jdk6 和 jdk7中调用substring时发生的事情并不一样。
2.3 JDK 6中的substring
String是通过字符数组实现的。在jdk 6 中,String类包含三个成员变量:char value[], int offset,int count。他们分别用来存储真正的字符数组,数组的第一个位置索引以及字符串中包含的字符个数。
当调用substring方法的时候,会创建一个新的string对象,但是这个string的值仍然指向堆中的同一个字符数组。这两个对象中只有count和offset 的值是不同的。
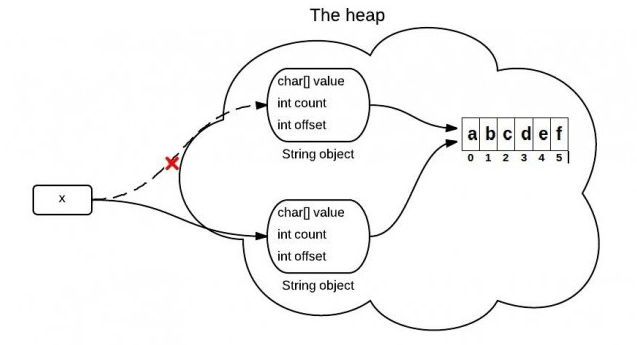
下面是证明上说观点的Java源码中的关键代码:
//JDK 6
String(int offset, int count, char value[]) {
this.value = value;
this.offset = offset;
this.count = count;
}
public String substring(int beginIndex, int endIndex) {
//check boundary
return new String(offset + beginIndex, endIndex - beginIndex, value);
}
2.4 JDK 6中的substring导致的问题
如果你有一个很长很长的字符串,但是当你使用substring进行切割的时候你只需要很短的一段。这可能导致性能问题,因为你需要的只是一小段字符序列,但是你却引用了整个字符串(因为这个非常长的字符数组一直在被引用,所以无法被回收,就可能导致内存泄露)。在JDK 6中,一般用以下方式来解决该问题,原理其实就是生成一个新的字符串并引用他。
x = x.substring(x, y) + ""
关于JDK 6中subString的使用不当会导致内存系列已经被官方记录在Java Bug Database中:
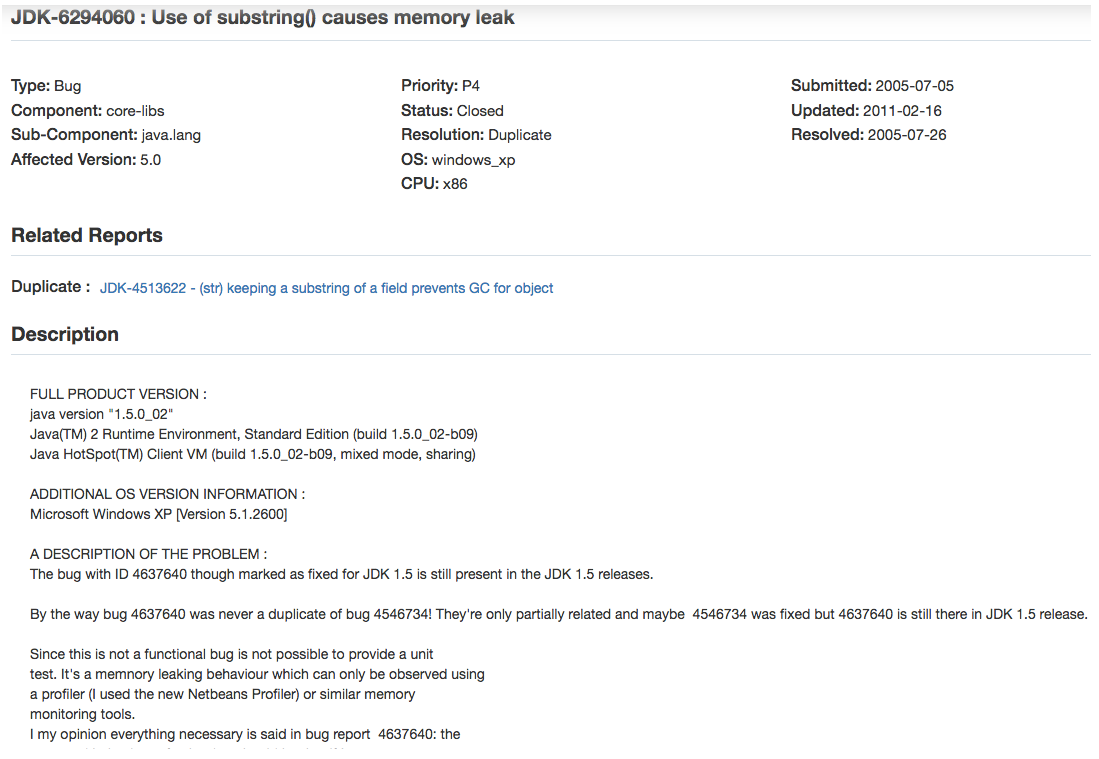
内存泄露
在计算机科学中,内存泄漏指由于疏忽或错误造成程序未能释放已经不再使用的内存。 内存泄漏并非指内存在物理上的消失,而是应用程序分配某段内存后,由于设计错误,导致在释放该段内存之前就失去了对该段内存的控制,从而造成了内存的浪费。
2.5 JDK 7 中的substring
上面提到的问题,在jdk 7中得到解决。在jdk 7 中,substring方法会在堆内存中创建一个新的数组。
Java源码中关于这部分的主要代码如下:
//JDK 7
public String(char value[], int offset, int count) {
//check boundary
this.value = Arrays.copyOfRange(value, offset, offset + count);
}
public String substring(int beginIndex, int endIndex) {
//check boundary
int subLen = endIndex - beginIndex;
return new String(value, beginIndex, subLen);
}
以上是JDK 7中的subString方法,其使用new String创建了一个新字符串,避免对老字符串的引用。从而解决了内存泄露问题。
所以,如果你的生产环境中使用的JDK版本小于1.7,当你使用String的subString方法时一定要注意,避免内存泄露。
3、replaceFirst、replaceAll、replace区别
3.1 区别
replace、replaceAll和replaceFirst是Java中常用的替换字符的方法,它们的方法定义是:
- replace(CharSequence target, CharSequence replacement) ,用replacement替换所有的target,两个参数都是字符串。
- replaceAll(String regex, String replacement) ,用replacement替换所有的regex匹配项,regex很明显是个正则表达式,replacement是字符串。
- replaceFirst(String regex, String replacement) ,基本和replaceAll相同,区别是只替换第一个匹配项。
可以看到,其中replaceAll以及replaceFirst是和正则表达式有关的,而replace和正则表达式无关。
replaceAll和replaceFirst的区别主要是替换的内容不同,replaceAll是替换所有匹配的字符,而replaceFirst()仅替换第一次出现的字符
3.2 用法例子
String string = "abc123adb23456aa";
System.out.println(string);
//abc123adb23456aa
//使用replace将a替换成H
System.out.println(string.replace("a","H"));
//Hbc123Hdb23456HH
//使用replaceFirst将第一个a替换成H
System.out.println(string.replaceFirst("a","H"));
//Hbc123adb23456aa
//使用replace将a替换成H
System.out.println(string.replaceAll("a","H"));
//Hbc123Hdb23456HH
//使用replaceFirst将第一个数字替换成H
System.out.println(string.replaceFirst("\d","H"));
//abcH23adb23456aa
//使用replaceAll将所有数字替换成H
System.out.println(string.replaceAll("\d","H"));
//abcHHHadbHHHHHaa
4、String对+的重载
运算符重载:在计算机程序设计中,运算符重载(英语:operator overloading)是多态的一种。运算符重载,就是对已有的运算符重新进行定义,赋予其另一种功能,以适应不同的数据类型。
语法糖
语法糖(Syntacticsugar),也译为糖衣语法,是由英国计算机科学家彼得·兰丁发明的一个术语,指计算机语言中添加的某种语法,这种语法对语言的功能没有影响,但是更方便程序员使用。语法糖让程序更加简洁,有更高的可读性。
详解
前面提到过,使用+拼接字符串,其实只是Java提供的一个语法糖, 那么,我们就来解一解这个语法糖,看看他的内部原理到底是如何实现的。
还是这样一段代码。我们把他生成的字节码进行反编译,看看结果。
String wechat = "Hollis";
String introduce = "每日更新Java相关技术文章";
String hollis = wechat + "," + introduce;
反编译后的内容如下,反编译工具为jad。
String wechat = "Hollis";
String introduce = "\u6BCF\u65E5\u66F4\u65B0Java\u76F8\u5173\u6280\u672F\u6587\u7AE0";//每日更新Java相关技术文章
String hollis = (new StringBuilder()).append(wechat).append(",").append(introduce).toString();
通过查看反编译以后的代码,我们可以发现,原来字符串常量在拼接过程中,是将String转成了StringBuilder后,使用其append方法进行处理的。
那么也就是说,Java中的+对字符串的拼接,其实现原理是使用StringBuilder.append。
但是,String的使用+字符串拼接也不全都是基于StringBuilder.append,还有种特殊情况,那就是如果是两个固定的字面量拼接,如:
String s = "a" + "b"
编译器会进行常量折叠(因为两个都是编译期常量,编译期可知),直接变成 String s = "ab"。
5、字符串拼接的几种方式和区别
5.1 字符串拼接
5.1.1 字符串不变性与字符串拼接
字符串拼接是我们在Java代码中比较经常要做的事情,就是把多个字符串拼接到一起。
我们都知道,String是Java中一个不可变的类,所以他一旦被实例化就无法被修改。
- 不可变类的实例一旦创建,其成员变量的值就不能被修改。这样设计有很多好处,比如可以缓存hashcode、使用更加便利以及更加安全等。
但是,既然字符串是不可变的,那么字符串拼接又是怎么回事呢?
其实,所有的所谓字符串拼接,都是重新生成了一个新的字符串。下面一段字符串拼接代码:
String s = "abcd";
s = s.concat("ef");
其实最后我们得到的s已经是一个新的字符串了。如下图
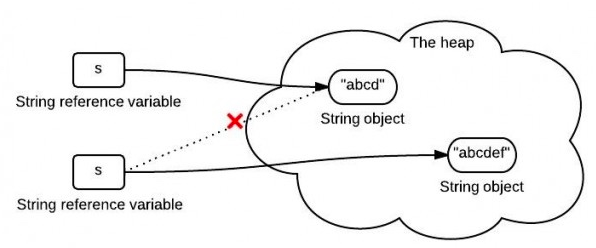
s中保存的是一个重新创建出来的String对象的引用。
那么,在Java中,到底如何进行字符串拼接呢?字符串拼接有很多种方式,这里简单介绍几种比较常用的。
5.1.2 使用+拼接字符串
在Java中,拼接字符串最简单的方式就是直接使用符号+来拼接。如:
String wechat = "Hollis";
String introduce = "每日更新Java相关技术文章";
String hollis = wechat + "," + introduce;
5.1.3 concat
除了使用+拼接字符串之外,还可以使用String类中的方法concat方法来拼接字符串。如:
String wechat = "Hollis";
String introduce = "每日更新Java相关技术文章";
String hollis = wechat.concat(",").concat(introduce);
5.1.4 StringBuffer
关于字符串,Java中除了定义了一个可以用来定义字符串常量的String类以外,还提供了可以用来定义字符串变量的StringBuffer类,它的对象是可以扩充和修改的。
使用StringBuffer可以方便的对字符串进行拼接。如:
StringBuffer wechat = new StringBuffer("Hollis");
String introduce = "每日更新Java相关技术文章";
StringBuffer hollis = wechat.append(",").append(introduce);
5.1.5 StringBuilder
除了StringBuffer以外,还有一个类StringBuilder也可以使用,其用法和StringBuffer类似。如:
StringBuilder wechat = new StringBuilder("Hollis");
String introduce = "每日更新Java相关技术文章";
StringBuilder hollis = wechat.append(",").append(introduce);
5.1.6 StringUtils.join
除了JDK中内置的字符串拼接方法,还可以使用一些开源类库中提供的字符串拼接方法名,如apache.commons中提供的StringUtils类,其中的join方法可以拼接字符串。
String wechat = "Hollis";
String introduce = "每日更新Java相关技术文章";
System.out.println(StringUtils.join(wechat, ",", introduce));
这里简单说一下,StringUtils中提供的join方法,最主要的功能是:将数组或集合以某拼接符拼接到一起形成新的字符串,如:
String []list ={"Hollis","每日更新Java相关技术文章"};
String result= StringUtils.join(list,",");
System.out.println(result);
//结果:Hollis,每日更新Java相关技术文章
并且,Java8中的String类中也提供了一个静态的join方法,用法和StringUtils.join类似。
以上就是比较常用的五种在Java种拼接字符串的方式,那么到底哪种更好用呢?为什么阿里巴巴Java开发手册中不建议在循环体中使用+进行字符串拼接呢?

5.2 使用+拼接字符串的实现原理
关于这个知识点,前面的章节介绍过,主要是通过StringBuilder的append方法实现的。
5.3 concat是如何实现的
我们再来看一下concat方法的源代码,看一下这个方法又是如何实现的。
public String concat(String str) {
int otherLen = str.length();
if (otherLen == 0) {
return this;
}
int len = value.length;
char buf[] = Arrays.copyOf(value, len + otherLen);
str.getChars(buf, len);
return new String(buf, true);
}
这段代码首先创建了一个字符数组,长度是已有字符串和待拼接字符串的长度之和,再把两个字符串的值复制到新的字符数组中,并使用这个字符数组创建一个新的String对象并返回。
通过源码我们也可以看到,经过concat方法,其实是new了一个新的String,这也就呼应到前面我们说的字符串的不变性问题上了。
5.4 StringBuffer和StringBuilder
接下来我们看看StringBuffer和StringBuilder的实现原理。
和String类类似,StringBuilder类也封装了一个字符数组,定义如下:
char[] value;
与String不同的是,它并不是final的,所以他是可以修改的。另外,与String不同,字符数组中不一定所有位置都已经被使用,它有一个实例变量,表示数组中已经使用的字符个数,定义如下:
int count;
其append源码如下:
public StringBuilder append(String str) {
super.append(str);
return this;
}
该类继承了AbstractStringBuilder类,看下其append方法:
public AbstractStringBuilder append(String str) {
if (str == null)
return appendNull();
int len = str.length();
ensureCapacityInternal(count + len);
str.getChars(0, len, value, count);
count += len;
return this;
}
append会直接拷贝字符到内部的字符数组中,如果字符数组长度不够,会进行扩展。
StringBuffer和StringBuilder类似,最大的区别就是StringBuffer是线程安全的,看一下StringBuffer的append方法。
public synchronized StringBuffer append(String str) {
toStringCache = null;
super.append(str);
return this;
}
该方法使用synchronized进行声明,说明是一个线程安全的方法。而StringBuilder则不是线程安全的。
5.5 StringUtils.join是如何实现的
通过查看StringUtils.join的源代码,我们可以发现,其实他也是通过StringBuilder来实现的。
public static String join(final Object[] array, String separator, final int startIndex, final int endIndex) {
if (array == null) {
return null;
}
if (separator == null) {
separator = EMPTY;
}
// endIndex - startIndex > 0: Len = NofStrings *(len(firstString) + len(separator))
// (Assuming that all Strings are roughly equally long)
final int noOfItems = endIndex - startIndex;
if (noOfItems <= 0) {
return EMPTY;
}
final StringBuilder buf = new StringBuilder(noOfItems * 16);
for (int i = startIndex; i < endIndex; i++) {
if (i > startIndex) {
buf.append(separator);
}
if (array[i] != null) {
buf.append(array[i]);
}
}
return buf.toString();
}
5.6 效率比较
既然有这么多种字符串拼接的方法,那么到底哪一种效率最高呢?我们来简单对比一下。
long t1 = System.currentTimeMillis();
//这里是初始字符串定义
for (int i = 0; i < 50000; i++) {
//这里是字符串拼接代码
}
long t2 = System.currentTimeMillis();
System.out.println("cost:" + (t2 - t1));
我们使用形如以上形式的代码,分别测试下五种字符串拼接代码的运行时间。得到结果如下:
+ cost:5119
StringBuilder cost:3
StringBuffer cost:4
concat cost:3623
StringUtils.join cost:25726
从结果可以看出,用时从短到长的对比是:
StringBuilder<StringBuffer<concat<+<StringUtils.join
StringBuffer在StringBuilder的基础上,做了同步处理,所以在耗时上会相对多一些。
StringUtils.join也是使用了StringBuilder,并且其中还是有很多其他操作,所以耗时较长,这个也容易理解。其实StringUtils.join更擅长处理字符串数组或者列表的拼接。
那么问题来了,前面我们分析过,其实使用+拼接字符串的实现原理也是使用的StringBuilder,那为什么结果相差这么多,高达1000多倍呢?
我们再把以下代码反编译下:
long t1 = System.currentTimeMillis();
String str = "hollis";
for (int i = 0; i < 50000; i++) {
String s = String.valueOf(i);
str += s;
}
long t2 = System.currentTimeMillis();
System.out.println("+ cost:" + (t2 - t1));
反编译后代码如下:
long t1 = System.currentTimeMillis();
String str = "hollis";
for(int i = 0; i < 50000; i++)
{
String s = String.valueOf(i);
str = (new StringBuilder()).append(str).append(s).toString();
}
long t2 = System.currentTimeMillis();
System.out.println((new StringBuilder()).append("+ cost:").append(t2 - t1).toString());
我们可以看到,反编译后的代码,在for循环中,每次都是new了一个StringBuilder,然后再把String转成StringBuilder,再进行append。
而频繁的新建对象当然要耗费很多时间了,不仅仅会耗费时间,频繁的创建对象,还会造成内存资源的浪费。
所以,阿里巴巴Java开发手册建议:循环体内,字符串的连接方式,使用 StringBuilder 的 append 方法进行扩展。而不要使用+。
5.7 总结
本文介绍了什么是字符串拼接,虽然字符串是不可变的,但是还是可以通过新建字符串的方式来进行字符串的拼接。
常用的字符串拼接方式有五种,分别是使用+、使用concat、使用StringBuilder、使用StringBuffer以及使用StringUtils.join。
由于字符串拼接过程中会创建新的对象,所以如果要在一个循环体中进行字符串拼接,就要考虑内存问题和效率问题。
因此,经过对比,我们发现,直接使用StringBuilder的方式是效率最高的。因为StringBuilder天生就是设计来定义可变字符串和字符串的变化操作的。
但是,还要强调的是:
- 如果不是在循环体中进行字符串拼接的话,直接使用+就好了。
- 如果在并发场景中进行字符串拼接的话,要使用StringBuffer来代替StringBuilder。
6、StringJoiner
6.1 介绍
StringJoiner是java.util包中的一个类,用于构造一个由分隔符分隔的字符序列(可选),并且可以从提供的前缀开始并以提供的后缀结尾。虽然这也可以在StringBuilder类的帮助下在每个字符串之后附加分隔符,但StringJoiner提供了简单的方法来实现,而无需编写大量代码。
StringJoiner类共有2个构造函数,5个公有方法。其中最常用的方法就是add方法和toString方法,类似于StringBuilder中的append方法和toString方法。
6.2 用法
StringJoiner的用法比较简单,下面的代码中,我们使用StringJoiner进行了字符串拼接。
public class StringJoinerTest {
public static void main(String[] args) {
StringJoiner hollis = new StringJoiner("Hollis");
hollis.add("hollischuang");
hollis.add("Java干货");
System.out.println(hollis);
StringJoiner sj1 = new StringJoiner(":", "[", "]");
sj1.add("Hollis").add("hollischuang").add("Java干货");
System.out.println(sj1.toString());
}
}
以上代码输出结果:
hollischuangHollisJava干货
[Hollis:hollischuang:Java干货]
值得注意的是,当我们StringJoiner(CharSequence delimiter)初始化一个StringJoiner的时候,这个delimiter其实是分隔符,并不是可变字符串的初始值。
StringJoiner(CharSequence delimiter,CharSequence prefix,CharSequence suffix)的第二个和第三个参数分别是拼接后的字符串的前缀和后缀。
6.3 原理
介绍了简单的用法之后,我们再来看看这个StringJoiner的原理,看看他到底是如何实现的。主要看一下add方法:
public StringJoiner add(CharSequence newElement) {
prepareBuilder().append(newElement);
return this;
}
private StringBuilder prepareBuilder() {
if (value != null) {
value.append(delimiter);
} else {
value = new StringBuilder().append(prefix);
}
return value;
}
看到了一个熟悉的身影——StringBuilder ,没错,StringJoiner其实就是依赖StringBuilder实现的。
当我们发现StringJoiner其实是通过StringBuilder实现之后,我们大概就可以猜到,他的性能损耗应该和直接使用StringBuilder差不多!
6.4 为什么需要StringJoiner
在了解了StringJoiner的用法和原理后,可能很多读者就会产生一个疑问,明明已经有一个StringBuilder了,为什么Java 8中还要定义一个StringJoiner呢?到底有什么好处呢?
如果读者足够了解Java 8的话,或许可以猜出个大概,这肯定和Stream有关。
作者也在Java doc:https://docs.oracle.com/javase/8/docs/api/java/util/StringJoiner.html 中找到了答案:
A StringJoiner may be employed to create formatted output from a Stream using Collectors.joining(CharSequence)
试想,在Java中,如果我们有这样一个List:
List<String> list = ImmutableList.of("Hollis","hollischuang","Java干货");
如果我们想要把他拼接成一个以下形式的字符串:
Hollis,hollischuang,Java干货
可以通过以下方式:
StringBuilder builder = new StringBuilder();
if (!list.isEmpty()) {
builder.append(list.get(0));
for (int i = 1, n = list.size(); i < n; i++) {
builder.append(",").append(list.get(i));
}
}
builder.toString();
还可以使用:
list.stream().reduce(new StringBuilder(), (sb, s) -> sb.append(s).append(','), StringBuilder::append).toString();
但是输出结果稍有些不同,需要进行二次处理:
Hollis,hollischuang,Java干货,
还可以使用"+"进行拼接:
list.stream().reduce((a,b)->a + "," + b).toString();
以上几种方式,要么是代码复杂,要么是性能不高,或者无法直接得到想要的结果。
为了满足类似这样的需求,Java 8中提供的StringJoiner就派上用场了。以上需求只需要一行代码:
list.stream().collect(Collectors.joining(":"));
即可。上面用的表达式中,Collectors.joining的源代码如下:
public static Collector<CharSequence, ?, String> joining(CharSequence delimiter,
CharSequence prefix,
CharSequence suffix) {
return new CollectorImpl<>(
() -> new StringJoiner(delimiter, prefix, suffix),
StringJoiner::add, StringJoiner::merge,
StringJoiner::toString, CH_NOID);
}
其实现原理就是借助了StringJoiner。
当然,或许在Collector中直接使用StringBuilder似乎也可以实现类似的功能,只不过稍微麻烦一些。所以,Java 8中提供了StringJoiner来丰富Stream的用法。
而且StringJoiner也可以方便的增加前缀和后缀,比如我们希望得到的字符串是[Hollis,hollischuang,Java干货]而不是Hollis,hollischuang,Java干货的话,StringJoiner的优势就更加明显了。
6.5 总结
本文介绍了Java 8中提供的可变字符串类——StringJoiner,可以用于字符串拼接。
StringJoiner其实是通过StringBuilder实现的,所以他的性能和StringBuilder差不多,他也是非线程安全的。
如果日常开发中中,需要进行字符串拼接,如何选择?
- 如果只是简单的字符串拼接,考虑直接使用"+"即可。
- 如果是在for循环中进行字符串拼接,考虑使用StringBuilder和StringBuffer。
- 如果是通过一个List进行字符串拼接,则考虑使用StringJoiner。
7、String.valueOf和Integer.toString的区别
我们有三种方式将一个int类型的变量变成一个String类型,那么他们有什么区别?
int i = 5;
String i1 = "" + i;
String i2 = String.valueOf(i);
String i3 = Integer.toString(i);
第三行和第四行没有任何区别,因为String.valueOf(i)也是调用Integer.toString(i)来实现的。
第二行代码其实是String i1 = (new StringBuilder()).append(i).toString();首先创建一个StringBuilder对象,然后再调用append方法,再调用toString方法。
8、switch对String的支持
switch支持这样几种数据类型:byte、short、int、 char、 String 。
8.1 switch对整型支持的实现
下面是一段很简单的Java代码,定义一个int型变量a,然后使用switch语句进行判断。执行这段代码输出内容为5,那么我们将下面这段代码反编译,看看他到底是怎么实现的。
public class switchDemoInt {
public static void main(String[] args) {
int a = 5;
switch (a) {
case 1:
System.out.println(1);
break;
case 5:
System.out.println(5);
break;
default:
break;
}
}
}
反编译后的代码如下:
public class switchDemoInt
{
public switchDemoInt()
{
}
public static void main(String args[])
{
int a = 5;
switch(a)
{
case 1: // '\001'
System.out.println(1);
break;
case 5: // '\005'
System.out.println(5);
break;
}
}
}
我们发现,反编译后的代码和之前的代码比较除了多了两行注释以外没有任何区别,那么我们就知道,switch对int的判断是直接比较整数的值。
8.2 switch对字符型支持的实现
直接上代码:
public class switchDemoInt {
public static void main(String[] args) {
char a = 'b';
switch (a) {
case 'a':
System.out.println('a');
break;
case 'b':
System.out.println('b');
break;
default:
break;
}
}
}
编译后的代码如下:
public class switchDemoChar
{
public switchDemoChar()
{
}
public static void main(String args[])
{
char a = 'b';
switch(a)
{
case 97: // 'a'
System.out.println('a');
break;
case 98: // 'b'
System.out.println('b');
break;
}
}
}
通过以上的代码作比较我们发现:对char类型进行比较的时候,实际上比较的是ascii码,编译器会把char型变量转换成对应的int型变量
8.3 switch对字符串支持的实现
还是先上代码:
public class switchDemoString {
public static void main(String[] args) {
String str = "world";
switch (str) {
case "hello":
System.out.println("hello");
break;
case "world":
System.out.println("world");
break;
default:
break;
}
}
}
对代码进行反编译:
public class switchDemoString
{
public switchDemoString()
{
}
public static void main(String args[])
{
String str = "world";
String s;
switch((s = str).hashCode())
{
default:
break;
case 99162322:
if(s.equals("hello"))
System.out.println("hello");
break;
case 113318802:
if(s.equals("world"))
System.out.println("world");
break;
}
}
}
看到这个代码,你知道原来字符串的switch是通过equals()和hashCode()方法来实现的。
记住,switch中只能使用整型,比如byte。short,char(ackii码是整型)以及int。还好hashCode()方法返回的是int,而不是long。通过这个很容易记住hashCode返回的是int这个事实。
仔细看下可以发现,进行switch的实际是哈希值,然后通过使用equals方法比较进行安全检查,这个检查是必要的,因为哈希可能会发生碰撞。
因此它的性能是不如使用枚举进行switch或者使用纯整数常量,但这也不是很差。
因为Java编译器只增加了一个equals方法,如果你比较的是字符串字面量的话会非常快,比如”abc” ==”abc”。如果你把hashCode()方法的调用也考虑进来了,那么还会再多一次的调用开销,因为字符串一旦创建了,它就会把哈希值缓存起来。
因此如果这个switch语句是用在一个循环里的,比如逐项处理某个值,或者游戏引擎循环地渲染屏幕,这里hashCode()方法的调用开销其实不会很大。
9、字符串常量池
9.1 介绍
String作为一个Java类,可以通过以下两种方式创建一个字符串:
String str = "Hollis";
String str = new String("Hollis");
而第一种是我们比较常用的做法,这种形式叫做字面量。
在JVM中,为了减少相同的字符串的重复创建,为了达到节省内存的目的。会单独开辟一块内存,用于保存字符串常量,这个内存区域被叫做字符串常量池。
当代码中出现双引号形式(字面量)创建字符串对象时,JVM 会先对这个字符串进行检查,如果字符串常量池中存在相同内容的字符串对象的引用,则将这个引用返回;否则,创建新的字符串对象,然后将这个引用放入字符串常量池,并返回该引用。
这种机制,就是字符串驻留或池化。
9.2 字符串常量池的位置
在JDK 7以前的版本中,字符串常量池是放在永久代中的。
因为按照计划,JDK会在后续的版本中通过元空间来代替永久代,所以首先在JDK 7中,将字符串常量池先从永久代中移出,暂时放到了堆内存中。
在JDK 8中,彻底移除了永久代,使用元空间替代了永久代,于是字符串常量池再次从堆内存移动到元空间中。
10、Class常量池
10.1 什么是Class文件
在《Java代码的编译与反编译那些事儿》https://www.hollischuang.com/archives/58 中我们介绍过Java的编译和反编译的概念。我们知道,计算机只认识0和1,所以程序员写的代码都需要经过编译成0和1构成的二进制格式才能够让计算机运行。
我们在《深入分析Java的编译原理》https://www.hollischuang.com/archives/2322 中提到过,为了让Java语言具有良好的跨平台能力,Java独具匠心的提供了一种可以在所有平台上都能使用的一种中间代码——字节码(ByteCode)。
有了字节码,无论是哪种平台(如Windows、Linux等),只要安装了虚拟机,都可以直接运行字节码。
同样,有了字节码,也解除了Java虚拟机和Java语言之间的耦合。这话可能很多人不理解,Java虚拟机不就是运行Java语言的么?这种解耦指的是什么?
其实,目前Java虚拟机已经可以支持很多除Java语言以外的语言了,如Groovy、JRuby、Jython、Scala等。之所以可以支持,就是因为这些语言也可以被编译成字节码。而虚拟机并不关心字节码是有哪种语言编译而来的。
Java语言中负责编译出字节码的编译器是一个命令是javac。
- javac是收录于JDK中的Java语言编译器。该工具可以将后缀名为.java的源文件编译为后缀名为.class的可以运行于Java虚拟机的字节码。
如,我们有以下简单的HelloWorld.java代码:
public class HelloWorld {
public static void main(String[] args) {
String s = "Hollis";
}
}
通过javac命令生成class文件:javac HelloWorld.java
生成HelloWorld.class文件:
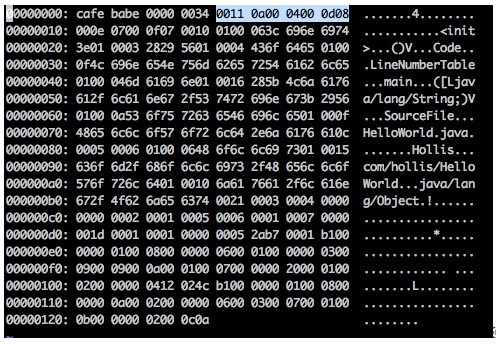
如何使用16进制打开class文件:使用 vim test.class ,然后在交互模式下,输入:%!xxd 即可。
可以看到,上面的文件就是Class文件,Class文件中包含了Java虚拟机指令集和符号表以及若干其他辅助信息。
要想能够读懂上面的字节码,需要了解Class类文件的结构,由于这不是本文的重点,这里就不展开说明了。
读者可以看到,HelloWorld.class文件中的前八个字母是cafe babe,这就是Class文件的魔数(Java中的”魔数”https://www.hollischuang.com/archives/491)
我们需要知道的是,在Class文件的4个字节的魔数后面的分别是4个字节的Class文件的版本号(第5、6个字节是次版本号,第7、8个字节是主版本号,我生成的Class文件的版本号是52,这时Java 8对应的版本。也就是说,这个版本的字节码,在JDK 1.8以下的版本中无法运行)在版本号后面的,就是Class常量池入口了。
10.2 Class常量池
Class常量池可以理解为是Class文件中的资源仓库。 Class文件中除了包含类的版本、字段、方法、接口等描述信息外,还有一项信息就是常量池(constant pool table),用于存放编译器生成的各种字面量(Literal)和符号引用(Symbolic References)。
由于不同的Class文件中包含的常量的个数是不固定的,所以在Class文件的常量池入口处会设置两个字节的常量池容量计数器,记录了常量池中常量的个数。

当然,还有一种比较简单的查看Class文件中常量池的方法,那就是通过javap命令。对于以上的HelloWorld.class,可以通过:javap -v HelloWorld.class
查看常量池内容如下:
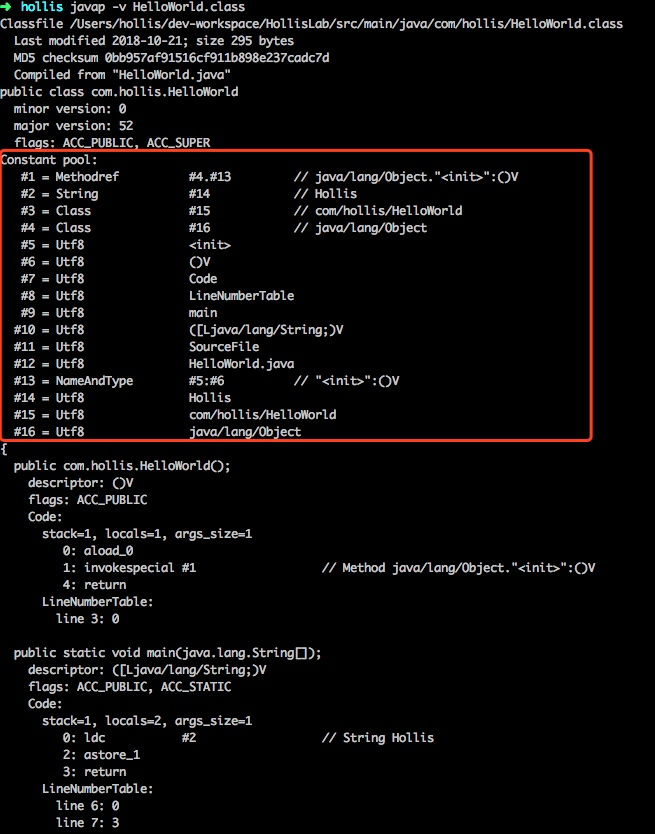
从上图中可以看到,反编译后的class文件常量池中共有16个常量。而Class文件中常量计数器的数值是0011,将该16进制数字转换成10进制的结果是17。
原因是与Java的语言习惯不同,常量池计数器是从1开始而不是从0开始的,常量池的个数是10进制的17,这就代表了其中有16个常量,索引值范围为1-16。
10.3 常量池中有什么
常量池中主要存放两大类常量:字面量(literal)和符号引用(symbolic references)。
10.3.1 字面量
前面说过,Class常量池中主要保存的是字面量和符号引用,那么到底什么字面量?
在计算机科学中,字面量(literal)是用于表达源代码中一个固定值的表示法(notation)。几乎所有计算机编程语言都具有对基本值的字面量表示,诸如:整数、浮点数以及字符串;而有很多也对布尔类型和字符类型的值也支持字面量表示;还有一些甚至对枚举类型的元素以及像数组、记录和对象等复合类型的值也支持字面量表示法。
以上是关于计算机科学中关于字面量的解释,并不是很容易理解。说简单点,字面量就是指由字母、数字等构成的字符串或者数值。
字面量只可以右值出现,所谓右值是指等号右边的值,如:int a=123这里的a为左值,123为右值。在这个例子中123就是字面量。
int a = 123;
String s = "hollis";
上面的代码事例中,123和hollis都是字面量。
10.3.2 符号引用
本文开头的HelloWorld代常量池中,除了字面量以外,还有符号引用,那么到底什么是符号引用呢。
符号引用是编译原理中的概念,是相对于直接引用来说的。主要包括了以下三类常量: * 类和接口的全限定名 * 字段的名称和描述符 * 方法的名称和描述符
这也就可以印证前面的常量池中还包含一些com/hollis/HelloWorld、main、([Ljava/lang/String;)V等常量的原因了。码中,Hollis就是一个字面量。
10.3.3 Class常量池有什么用
前面介绍了这么多,关于Class常量池是什么,怎么查看Class常量池以及Class常量池中保存了哪些东西。有一个关键的问题没有讲,那就是Class常量池到底有什么用。
首先,可以明确的是,Class常量池是Class文件中的资源仓库,其中保存了各种常量。而这些常量都是开发者定义出来,需要在程序的运行期使用的。
在《深入理解Java虚拟》中有这样的表述:
Java代码在进行Javac编译的时候,并不像C和C++那样有“连接”这一步骤,而是在虚拟机加载Class文件的时候进行动态连接。也就是说,在Class文件中不会保存各个方法、字段的最终内存布局信息,因此这些字段、方法的符号引用不经过运行期转换的话无法得到真正的内存入口地址,也就无法直接被虚拟机使用。当虚拟机运行时,需要从常量池获得对应的符号引用,再在类创建时或运行时解析、翻译到具体的内存地址之中。关于类的创建和动态连接的内容,在虚拟机类加载过程时再进行详细讲解。
前面这段话,看起来很绕,不是很容易理解。其实他的意思就是: Class是用来保存常量的一个媒介场所,并且是一个中间场所。在JVM真的运行时,需要把常量池中的常量加载到内存中。
至于到底哪个阶段会做这件事情,以及Class常量池中的常量会以何种方式被加载到具体什么地方,会在本系列文章的后续内容中继续阐述。欢迎关注我的博客(http://www.hollischuang.com) 和公众号(Hollis),即可第一时间获得最新内容。
另外,关于常量池中常量的存储形式,以及数据类型的表示方法本文中并未涉及,并不是说这部分知识点不重要,只是Class字节码的分析本就枯燥,作者不想在一篇文章中给读者灌输太多的理论上的内容。感兴趣的读者可以自行Google学习,如果真的有必要,我也可以单独写一篇文章再深入介绍。
11、运行时常量池
11.1 概述
运行时常量池( Runtime Constant Pool)是每一个类或接口的常量池( Constant_Pool)的运行时表示形式。
它包括了若干种不同的常量:从编译期可知的数值字面量到必须运行期解析后才能获得的方法或字段引用。运行时常量池扮演了类似传统语言中符号表( SymbolTable)的角色,不过它存储数据范围比通常意义上的符号表要更为广泛。
每一个运行时常量池都分配在 Java 虚拟机的方法区之中,在类和接口被加载到虚拟机后,对应的运行时常量池就被创建出来。
以上,是Java虚拟机规范中关于运行时常量池的定义。
11.2 运行时常量池在JDK各个版本中的实现
根据Java虚拟机规范约定:每一个运行时常量池都在Java虚拟机的方法区中分配,在加载类和接口到虚拟机后,就创建对应的运行时常量池。
在不同版本的JDK中,运行时常量池所处的位置也不一样。以HotSpot为例:
在JDK 1.7之前,方法区位于堆内存的永久代中,运行时常量池作为方法区的一部分,也处于永久代中。
因为使用永久代实现方法区可能导致内存泄露问题,所以,从JDK1.7开始,JVM尝试解决这一问题,在1.7中,将原本位于永久代中的运行时常量池移动到堆内存中。(永久代在JDK 1.7并没有完全移除,只是原来方法区中的运行时常量池、类的静态变量等移动到了堆内存中。)
在JDK 1.8中,彻底移除了永久代,方法区通过元空间的方式实现。随之,运行时常量池也在元空间中实现。
11.3 运行时常量池中常量的来源
编译期可知的字面量和符号引用(来自Class常量池) 运行期解析后可获得的常量(如String的intern方法);
所以,运行时常量池中的内容包含:Class常量池中的常量、字符串常量池中的内容
11.4 运行时常量池、Class常量池、字符串常量池的区别与联系
虚拟机启动过程中,会将各个Class文件中的常量池载入到运行时常量池中。
所以,Class常量池只是一个媒介场所。在JVM真的运行时,需要把常量池中的常量加载到内存中,进入到运行时常量池。
字符串常量池可以理解为运行时常量池分出来的部分。加载时,对于class的静态常量池,如果字符串会被装到字符串常量池中。
12、intern
在JVM中,为了减少相同的字符串的重复创建,为了达到节省内存的目的。会单独开辟一块内存,用于保存字符串常量,这个内存区域被叫做字符串常量池。
当代码中出现双引号形式(字面量)创建字符串对象时,JVM 会先对这个字符串进行检查,如果字符串常量池中存在相同内容的字符串对象的引用,则将这个引用返回;否则,创建新的字符串对象,然后将这个引用放入字符串常量池,并返回该引用。
除了以上方式之外,还有一种可以在运行期将字符串内容放置到字符串常量池的办法,那就是使用intern
intern的功能很简单:
在每次赋值的时候使用 String 的 intern 方法,如果常量池中有相同值,就会重复使用该对象,返回对象引用。
13、String有没有长度限制
13.1 String的长度限制
String类中有很多重载的构造函数,其中有几个是支持用户传入length来执行长度的:
public String(byte bytes[], int offset, int length)
可以看到,这里面的参数length是使用int类型定义的,那么也就是说,String定义的时候,最大支持的长度就是int的最大范围值。
根据Integer类的定义,java.lang.Integer#MAX_VALUE的最大值是2^31 - 1;
那么,我们是不是就可以认为String能支持的最大长度就是这个值了呢?
其实并不是,这个值只是在运行期,我们构造String的时候可以支持的一个最大长度,而实际上,在编译期,定义字符串的时候也是有长度限制的。
如以下代码:
String s = "11111...1111";//其中有10万个字符"1"
当我们使用如上形式定义一个字符串的时候,当我们执行javac编译时,是会抛出异常的,提示如下:
错误: 常量字符串过长
那么,明明String的构造函数指定的长度是可以支持2147483647(2^31 - 1)的,为什么像以上形式定义的时候无法编译呢?
其实,形如String s = "xxx";定义String的时候,xxx被我们称之为字面量,这种字面量在编译之后会以常量的形式进入到Class常量池。
那么问题就来了,因为要进入常量池,就要遵守常量池的有关规定。
13.2 常量池限制
我们知道,javac是将Java文件编译成class文件的一个命令,那么在Class文件生成过程中,就需要遵守一定的格式。
根据《Java虚拟机规范》中第4.4章节常量池的定义,CONSTANT_String_info 用于表示 java.lang.String 类型的常量对象,格式如下:
CONSTANT_String_info {
u1 tag;
u2 string_index;
}
其中,string_index 项的值必须是对常量池的有效索引, 常量池在该索引处的项必须是 CONSTANT_Utf8_info 结构,表示一组 Unicode 码点序列,这组 Unicode 码点序列最终会被初始化为一个 String 对象。
CONSTANT_Utf8_info 结构用于表示字符串常量的值:
CONSTANT_Utf8_info {
u1 tag;
u2 length;
u1 bytes[length];
}
其中,length则指明了 bytes[]数组的长度,其类型为u2,
通过翻阅《规范》,我们可以获悉。u2表示两个字节的无符号数,那么1个字节有8位,2个字节就有16位。
16位无符号数可表示的最大值位2^16 - 1 = 65535。
也就是说,Class文件中常量池的格式规定了,其字符串常量的长度不能超过65535。
那么,我们尝试使用以下方式定义字符串:
String s = "11111...1111";//其中有65535个字符"1"
尝试使用javac编译,同样会得到"错误: 常量字符串过长",那么原因是什么呢?
其实,这个原因在javac的代码中是可以找到的,在Gen类中有如下代码:
private void checkStringConstant(DiagnosticPosition var1, Object var2) {
if (this.nerrs == 0 && var2 != null && var2 instanceof String && ((String)var2).length() >= 65535) {
this.log.error(var1, "limit.string", new Object[0]);
++this.nerrs;
}
}
代码中可以看出,当参数类型为String,并且长度大于等于65535的时候,就会导致编译失败。
这个地方大家可以尝试着debug一下javac的编译过程,也可以发现这个地方会报错。
如果我们尝试以65534个字符定义字符串,则会发现可以正常编译。
13.3 运行期限制
上面提到的这种String长度的限制是编译期的限制,也就是使用String s= “”;这种字面值方式定义的时候才会有的限制。
那么。String在运行期有没有限制呢,答案是有的,就是我们前文提到的那个Integer.MAX_VALUE ,这个值约等于4G,在运行期,如果String的长度超过这个范围,就可能会抛出异常。(在jdk 1.9之前)
int 是一个 32 位变量类型,取正数部分来算的话,他们最长可以有
2^31-1 =2147483647 个 16-bit Unicodecharacter
2147483647 * 16 = 34359738352 位
34359738352 / 8 = 4294967294 (Byte)
4294967294 / 1024 = 4194303.998046875 (KB)
4194303.998046875 / 1024 = 4095.9999980926513671875 (MB)
4095.9999980926513671875 / 1024 = 3.99999999813735485076904296875 (GB)
有近 4G 的容量。
很多人会有疑惑,编译的时候最大长度都要求小于65535了,运行期怎么会出现大于65535的情况呢。这其实很常见,如以下代码:
String s = "";
for (int i = 0; i <100000 ; i++) {
s+="i";
}
得到的字符串长度就有10万,另外我之前在实际应用中遇到过这个问题。
之前一次系统对接,需要传输高清图片,约定的传输方式是对方将图片转成BASE64编码,我们接收到之后再转成图片。
在将BASE64编码后的内容赋值给字符串的时候就抛了异常。
13.4 总结
字符串有长度限制,在编译期,要求字符串常量池中的常量不能超过65535,并且在javac执行过程中控制了最大值为65534。
在运行期,长度不能超过Int的范围,否则会抛异常。
最后,这个知识点 ,我录制了视频(https://www.bilibili.com/video/BV1uK4y1t7H1/)