第12章_序列化
1、什么是序列化与反序列化
1.1 简介
序列化是将对象转换为可传输格式的过程。 是一种数据的持久化手段。一般广泛应用于网络传输,RMI和RPC等场景中。
反序列化是序列化的逆操作。
序列化是将对象的状态信息转换为可存储或传输的形式的过程。一般是以字节码或XML格式传输。而字节码或XML编码格式可以还原为完全相等的对象。这个相反的过程称为反序列化。
1.2 Java如何实现序列化与反序列化
相关信息
Java对象的序列化与反序列化
在Java中,我们创建出来的这些Java对象都是存在于JVM的堆内存中的。只有JVM处于运行状态的时候,这些对象才可能存在。一旦JVM停止运行,这些对象的状态也就随之而丢失了。
但是在真实的应用场景中,我们需要将这些对象持久化下来,并且能够在需要的时候把对象重新读取出来。Java的对象序列化可以帮助我们实现该功能。
对象序列化机制(object serialization)是Java语言内建的一种对象持久化方式,通过对象序列化,可以把对象的状态保存为字节数组,并且可以在有需要的时候将这个字节数组通过反序列化的方式再转换成对象。对象序列化可以很容易的在JVM中的活动对象和字节数组(流)之间进行转换。
在Java中,对象的序列化与反序列化被广泛应用到RMI(远程方法调用)及网络传输中。
相关信息
相关接口及类
- java.io.Serializable
- java.io.Externalizable
- ObjectOutput
- ObjectInput
- ObjectOutputStream
- ObjectInputStream
推荐阅读
深入分析Java的序列化与反序列化:https://www.hollischuang.com/archives/1140
单例与序列化的那些事儿:https://www.hollischuang.com/archives/1144
1.3 Serializable 接口
类通过实现 java.io.Serializable 接口以启用其序列化功能。未实现此接口的类将无法使其任何状态序列化或反序列化。可序列化类的所有子类型本身都是可序列化的。
序列化接口没有方法或字段,仅用于标识可序列化的语义。 (该接口并没有方法和字段,为什么只有实现了该接口的类的对象才能被序列化呢?https://www.hollischuang.com/archives/1140#What Serializable Did)
当试图对一个对象进行序列化的时候,如果遇到不支持 Serializable 接口的对象。在此情况下,将抛出 NotSerializableException。
如果要序列化的类有父类,要想同时将在父类中定义过的变量持久化下来,那么父类也应该集成java.io.Serializable接口。
下面是一个实现了java.io.Serializable接口的类。
package com.hollischaung.serialization.SerializableDemos;
import java.io.Serializable;
/**
* Created by hollis on 16/2/17.
* 实现Serializable接口
*/
public class User1 implements Serializable {
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "User{" +
"name='" + name + ''' +
", age=" + age +
'}';
}
}
通过下面的代码进行序列化及反序列化
package com.hollischaung.serialization.SerializableDemos;
import org.apache.commons.io.FileUtils;
import org.apache.commons.io.IOUtils;
import java.io.*;
/**
* Created by hollis on 16/2/17.
* SerializableDemo1 结合SerializableDemo2说明 一个类要想被序列化必须实现Serializable接口
*/
public class SerializableDemo1 {
public static void main(String[] args) {
//Initializes The Object
User1 user = new User1();
user.setName("hollis");
user.setAge(23);
System.out.println(user);
//Write Obj to File
ObjectOutputStream oos = null;
try {
oos = new ObjectOutputStream(new FileOutputStream("tempFile"));
oos.writeObject(user);
}
catch (IOException e) {
e.printStackTrace();
}
finally {
IOUtils.closeQuietly(oos);
}
//Read Obj from File
File file = new File("tempFile");
ObjectInputStream ois = null;
try {
ois = new ObjectInputStream(new FileInputStream(file));
User1 newUser = (User1) ois.readObject();
System.out.println(newUser);
}
catch (IOException e) {
e.printStackTrace();
}
catch (ClassNotFoundException e) {
e.printStackTrace();
}
finally {
IOUtils.closeQuietly(ois);
try {
FileUtils.forceDelete(file);
}
catch (IOException e) {
e.printStackTrace();
}
}
}
}
输出:
User{name='hollis', age=23}
User{name='hollis', age=23}
1.4 Externalizable接口
除了Serializable之外,java中还提供了另一个序列化接口Externalizable。
为了了解Externalizable接口和Serializable接口的区别,先来看代码,我们把上面的代码改成使用Externalizable的形式。
package com.hollischaung.serialization.ExternalizableDemos;
import java.io.Externalizable;
import java.io.IOException;
import java.io.ObjectInput;
import java.io.ObjectOutput;
/**
* Created by hollis on 16/2/17.
* 实现Externalizable接口
*/
public class User1 implements Externalizable {
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public void writeExternal(ObjectOutput out) throws IOException {
}
public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException {
}
@Override
public String toString() {
return "User{" +
"name='" + name + ''' +
", age=" + age +
'}';
}
}
package com.hollischaung.serialization.ExternalizableDemos;
import java.io.*;
/**
* Created by hollis on 16/2/17.
*/
public class ExternalizableDemo1 {
//为了便于理解和节省篇幅,忽略关闭流操作及删除文件操作。真正编码时千万不要忘记
//IOException直接抛出
public static void main(String[] args) throws IOException, ClassNotFoundException {
//Write Obj to file
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("tempFile"));
User1 user = new User1();
user.setName("hollis");
user.setAge(23);
oos.writeObject(user);
//Read Obj from file
File file = new File("tempFile");
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(file));
User1 newInstance = (User1) ois.readObject();
//output
System.out.println(newInstance);
}
}
输出:User
通过上面的实例可以发现,对User1类进行序列化及反序列化之后得到的对象的所有属性的值都变成了默认值。也就是说,之前的那个对象的状态并没有被持久化下来。这就是Externalizable接口和Serializable接口的区别:
- Externalizable继承了Serializable,该接口中定义了两个抽象方法:writeExternal()与readExternal()。当使用Externalizable接口来进行序列化与反序列化的时候需要开发人员重写writeExternal()与readExternal()方法。由于上面的代码中,并没有在这两个方法中定义序列化实现细节,所以输出的内容为空。
- 还有一点值得注意:在使用Externalizable进行序列化的时候,在读取对象时,会调用被序列化类的无参构造器去创建一个新的对象,然后再将被保存对象的字段的值分别填充到新对象中。所以,实现Externalizable接口的类必须要提供一个public的无参的构造器。
按照要求修改之后代码如下:
package com.hollischaung.serialization.ExternalizableDemos;
import java.io.Externalizable;
import java.io.IOException;
import java.io.ObjectInput;
import java.io.ObjectOutput;
/**
* Created by hollis on 16/2/17.
* 实现Externalizable接口,并实现writeExternal和readExternal方法
*/
public class User2 implements Externalizable {
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public void writeExternal(ObjectOutput out) throws IOException {
out.writeObject(name);
out.writeint(age);
}
public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException {
name = (String) in.readObject();
age = in.readint();
}
@Override
public String toString() {
return "User{" +
"name='" + name + ''' +
", age=" + age +
'}';
}
}
package com.hollischaung.serialization.ExternalizableDemos;
import java.io.*;
/**
* Created by hollis on 16/2/17.
*/
public class ExternalizableDemo2 {
//为了便于理解和节省篇幅,忽略关闭流操作及删除文件操作。真正编码时千万不要忘记
//IOException直接抛出
public static void main(String[] args) throws IOException, ClassNotFoundException {
//Write Obj to file
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("tempFile"));
User2 user = new User2();
user.setName("hollis");
user.setAge(23);
oos.writeObject(user);
//Read Obj from file
File file = new File("tempFile");
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(file));
User2 newInstance = (User2) ois.readObject();
//output
System.out.println(newInstance);
}
}
输出:User
这次,就可以把之前的对象状态持久化下来了。
如果User类中没有无参数的构造函数,在运行时会抛出异常:java.io.InvalidClassException
1.5 Serializable和Externalizable有何不同
Java中的类通过实现 java.io.Serializable接口以启⽤其序列化功能。 未实现此接口的类将⽆法使其任何状态序列化或反序列化。
- 可序列化类的所有⼦类型本⾝都是可序列化的。
- 序列化接口没有⽅法或字段, 仅⽤于标识可序列化的语义。
- 不⽀持Serializable 接口的对象,将抛NotSerializableException。
- 如果要序列化的类有⽗类, 要想同时将在⽗类中定义过的变量持久化下来, 那么⽗类也应该集成java.io.Serializable接口。
Externalizable继承了Serializable
- 该接口中定义了两个抽象⽅法:writeExternal()与readExternal()。 当使⽤Externalizable接口来进⾏序列化与反序列化的时候需要开发⼈员重写writeExternal()与readExternal()⽅法。
- 如果没有在这两个⽅法中定义序列化实现细节, 那么序列化之后, 对象内容为空。
- 实现Externalizable接口的类必须要提供⼀个public的⽆参的构造器。
- 所以, 实现Externalizable, 并实现writeExternal()和readExternal()⽅法可以指定序列化哪些属性。
2、什么是transient
ArrayList类和Vector类都是使用数组实现的,但是在定义数组elementData这个属性时稍有不同,那就是ArrayList使用transient关键字。
private transient Object[] elementData;
protected Object[] elementData;
transient作用
简单点说,就是被transient修饰的成员变量,在序列化的时候其值会被忽略,在被反序列化后, transient变量的值被设为初始值,如int型的是0,对象型的是null。
Java语言的关键字,变量修饰符,如果用transient声明一个实例变量,当对象存储时,它的值不需要维持。这里的对象存储是指,Java的serialization提供的一种持久化对象实例的机制。当一个对象被序列化的时候,transient型变量的值不包括在序列化的表示中,然而非transient型的变量是被包括进去的。使用情况是:当持久化对象时,可能有一个特殊的对象数据成员(如用户的密码,银行卡号等),我们不想用serialization机制来保存它。为了在一个特定对象的一个域上关闭serialization,可以在这个域前加上关键字transient。
注意static修饰的静态变量天然就是不可序列化的。
transient关键字只能修饰变量,而不能修饰方法和类。注意,本地变量是不能被transient关键字修饰的。变量如果是用户自定义类变量,则该类需要实现Serializable接口。
一个静态变量不管是否被transient修饰,均不能被序列化(如果反序列化后类中static变量还有值,则值为当前JVM中对应static变量的值)。序列化保存的是对象状态,静态变量保存的是类状态,因此序列化并不保存静态变量。 参考:https://blog.csdn.net/u012723673/article/details/80699029
3、序列化底层原理
3.1 前论
通过ArrayList的序列化来开展介绍Java是如何实现序列化及反序列化。先考虑一个问题,如何自定义的序列化和反序列化策略?
带着这个问题,我们来看java.util.ArrayList的源码:
code 3
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
private static final long serialVersionUID = 8683452581122892189L;
transient Object[] elementData;
// non-private to simplify nested class access
private int size;
}
笔者省略了其他成员变量,从上面的代码中可以知道ArrayList实现了java.io.Serializable接口,那么我们就可以对它进行序列化及反序列化。因为elementData是transient的,所以我们认为这个成员变量不会被序列化而保留下来。我们写一个Demo,验证一下我们的想法:
code 4
public static void main(String[] args) throws IOException, ClassNotFoundException {
List<String> stringList = new ArrayList<String>();
stringList.add("hello");
stringList.add("world");
stringList.add("hollis");
stringList.add("chuang");
System.out.println("init StringList" + stringList);
ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream("stringlist"));
objectOutputStream.writeObject(stringList);
IOUtils.close(objectOutputStream);
File file = new File("stringlist");
ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream(file));
List<String> newStringList = (List<String>)objectInputStream.readObject();
IOUtils.close(objectInputStream);
if(file.exists()){
file.delete();
}
System.out.println("new StringList" + newStringList);
}
//init StringList[hello, world, hollis, chuang]
//new StringList[hello, world, hollis, chuang]
了解ArrayList的人都知道,ArrayList底层是通过数组实现的。那么数组elementData其实就是用来保存列表中的元素的。通过该属性的声明方式我们知道,他是无法通过序列化持久化下来的。那么为什么code 4的结果却通过序列化和反序列化把List中的元素保留下来了呢?
3.2 writeObject 和 readObject方法
在ArrayList中定义了来个方法: writeObject和readObject。
这里先给出结论:
- 在序列化过程中,如果被序列化的类中定义了writeObject 和 readObject 方法,虚拟机会试图调用对象类里的 writeObject 和 readObject 方法,进行用户自定义的序列化和反序列化。
- 如果没有这样的方法,则默认调用是 ObjectOutputStream 的 defaultWriteObject 方法以及 ObjectInputStream 的 defaultReadObject 方法。
- 用户自定义的 writeObject 和 readObject 方法可以允许用户控制序列化的过程,比如可以在序列化的过程中动态改变序列化的数值。
来看一下这两个方法的具体实现:
code 5
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
elementData = EMPTY_ELEMENTDATA;
// Read in size, and any hidden stuff
s.defaultReadObject();
// Read in capacity
s.readint();
// ignored
if (size > 0) {
// be like clone(), allocate array based upon size not capacity
ensureCapacityInternal(size);
Object[] a = elementData;
// Read in all elements in the proper order.
for (int i=0; i<size; i++) {
a[i] = s.readObject();
}
}
}
code 6
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
// Write out element count, and any hidden stuff
int expectedModCount = modCount;
s.defaultWriteObject();
// Write out size as capacity for behavioural compatibility with clone()
s.writeint(size);
// Write out all elements in the proper order.
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
那么为什么ArrayList要用这种方式来实现序列化呢?
3.3 为什么使用transient
ArrayList实际上是动态数组,每次在放满以后自动增长设定的长度值,如果数组自动增长长度设为100,而实际只放了一个元素,那就会序列化99个null元素。为了保证在序列化的时候不会将这么多null同时进行序列化,ArrayList把元素数组设置为transient。
3.4 为什么重写writeObject 和 readObject
为了防止一个包含大量空对象的数组被序列化,为了优化存储,所以,ArrayList使用transient来声明elementData。但是,作为一个集合,在序列化过程中还必须保证其中的元素可以被持久化下来,所以,通过重写writeObject 和 readObject方法的方式把其中的元素保留下来。
writeObject方法把elementData数组中的元素遍历的保存到输出流(ObjectOutputStream)中。
readObject方法从输入流(ObjectInputStream)中读出对象并保存赋值到elementData数组中。
3.5 如何自定义序列化和反序列化策略
答:可以通过在被序列化的类中增加writeObject和readObject方法。
那么问题又来了:
- 虽然ArrayList中写了writeObject 和 readObject 方法,但是这两个方法并没有显示的被调用啊。
- 那么如果一个类中包含writeObject 和 readObject方法,那么这两个方法是怎么被调用的呢?
3.6 ObjectOutputStream
从code 4中,我们可以看出,对象的序列化过程通过ObjectOutputStream和ObjectInputputStream来实现的,那么带着刚刚的问题,我们来分析一下ArrayList中的writeObject 和 readObject 方法到底是如何被调用的呢?
为了节省篇幅,这里给出ObjectOutputStream的writeObject的调用栈:
writeObject ---> writeObject0 --->writeOrdinaryObject--->writeSerialData--->invokeWriteObject
这里看一下invokeWriteObject:
void invokeWriteObject(Object obj, ObjectOutputStream out)
throws IOException, UnsupportedOperationException
{
if (writeObjectMethod != null) {
try {
writeObjectMethod.invoke(obj, new Object[]{
out
}
);
}
catch (InvocationTargetException ex) {
Throwable th = ex.getTargetException();
if (th instanceof IOException) {
throw (IOException) th;
} else {
throwMiscException(th);
}
}
catch (IllegalAccessException ex) {
// should not occur, as access checks have been suppressed
throw new InternalError(ex);
}
} else {
throw new UnsupportedOperationException();
}
}
其中writeObjectMethod.invoke(obj, new Object[]{ out });是关键,通过反射的方式调用writeObjectMethod方法。官方是这么解释这个writeObjectMethod的:
class-defined writeObject method, or null if none
在我们的例子中,这个方法就是我们在ArrayList中定义的writeObject方法。通过反射的方式被调用了。
如果一个类中包含writeObject和readObject方法,那么这两个方法是怎么被调用的?
答:在使用ObjectOutputStream的writeObject方法和ObjectInputStream的readObject方法时,会通过反射的方式调用。
Serializable明明就是一个空的接口,它是怎么保证只有实现了该接口的方法才能进行序列化与反序列化的呢?
Serializable接口的定义:
public interface Serializable {
}
读者可以尝试把code 1中的继承Serializable的代码去掉,再执行code 2,会抛出java.io.NotSerializableException。
其实这个问题也很好回答,我们再回到刚刚ObjectOutputStream的writeObject的调用栈:
writeObject ---> writeObject0 --->writeOrdinaryObject--->writeSerialData--->invokeWriteObject
writeObject0方法中有这么一段代码:
if (obj instanceof String) {
writeString((String) obj, unshared);
} else if (cl.isArray()) {
writeArray(obj, desc, unshared);
} else if (obj instanceof Enum) {
writeEnum((Enum<?>) obj, desc, unshared);
} else if (obj instanceof Serializable) {
writeOrdinaryObject(obj, desc, unshared);
} else {
if (extendedDebugInfo) {
throw new NotSerializableException(
cl.getName() + "n" + debugInfoStack.toString());
} else {
throw new NotSerializableException(cl.getName());
}
}
在进行序列化操作时,会判断要被序列化的类是否是Enum、Array和Serializable类型,如果不是则直接抛出NotSerializableException。
3.7 总结
- 如果一个类想被序列化,需要实现Serializable接口。否则将抛出NotSerializableException异常,这是因为,在序列化操作过程中会对类型进行检查,要求被序列化的类必须属于Enum、Array和Serializable类型其中的任何一种。
- 在变量声明前加上该关键字,可以阻止该变量被序列化到文件中。
- 在类中增加writeObject和readObject方法可以实现自定义序列化策略
4、为什么serialVersionUID不能随便改
4.1 什么是serialVersionUID
序列化是将对象的状态信息转换为可存储或传输的形式的过程。我们都知道,Java对象是保存在JVM的堆内存中的,也就是说,如果JVM堆不存在了,那么对象也就跟着消失了。
而序列化提供了一种方案,可以让你在即使JVM停机的情况下也能把对象保存下来的方案。就像我们平时用的U盘一样。把Java对象序列化成可存储或传输的形式(如二进制流),比如保存在文件中。这样,当再次需要这个对象的时候,从文件中读取出二进制流,再从二进制流中反序列化出对象。
虚拟机是否允许反序列化,不仅取决于类路径和功能代码是否一致,一个非常重要的一点是两个类的序列化 ID 是否一致,这个所谓的序列化ID,就是我们在代码中定义的serialVersionUID。
4.2 如果serialVersionUID变了会怎样
我们举个例子吧,看看如果serialVersionUID被修改了会发生什么?
代码块:
public class SerializableDemo1 {
public static void main(String[] args) {
//Initializes The Object
User1 user = new User1();
user.setName("hollis");
//Write Obj to File
ObjectOutputStream oos = null;
try {
oos = new ObjectOutputStream(new FileOutputStream("tempFile"));
oos.writeObject(user);
}
catch (IOException e) {
e.printStackTrace();
}
finally {
IOUtils.closeQuietly(oos);
}
}
}
class User1 implements Serializable {
private static final long serialVersionUID = 1L;
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
我们先执行以上代码,把一个User1对象写入到文件中。然后我们修改一下User1类,把serialVersionUID的值改为2L。
代码块:
class User1 implements Serializable {
private static final long serialVersionUID = 2L;
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
然后执行以下代码,把文件中的对象反序列化出来:
代码块:
public class SerializableDemo2 {
public static void main(String[] args) {
//Read Obj from File
File file = new File("tempFile");
ObjectInputStream ois = null;
try {
ois = new ObjectInputStream(new FileInputStream(file));
User1 newUser = (User1) ois.readObject();
System.out.println(newUser);
}
catch (IOException e) {
e.printStackTrace();
}
catch (ClassNotFoundException e) {
e.printStackTrace();
}
finally {
IOUtils.closeQuietly(ois);
try {
FileUtils.forceDelete(file);
}
catch (IOException e) {
e.printStackTrace();
}
}
}
}
执行结果如下:
java.io.InvalidClassException: com.hollis.User1; local class incompatible: stream classdesc serialVersionUID = 1, local class serialVersionUID = 2
可以发现,以上代码抛出了一个java.io.InvalidClassException,并且指出serialVersionUID不一致。
这是因为,在进行反序列化时,JVM会把传来的字节流中的serialVersionUID与本地相应实体类的serialVersionUID进行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常,即是InvalidCastException。
这也是《阿里巴巴Java开发手册》中规定,在兼容性升级中,在修改类的时候,不要修改serialVersionUID的原因。除非是完全不兼容的两个版本。所以,serialVersionUID其实是验证版本一致性的。
如果读者感兴趣,可以把各个版本的JDK代码都拿出来看一下,那些向下兼容的类的serialVersionUID是没有变化过的。比如String类的serialVersionUID一直都是-6849794470754667710L。
但是,作者认为,这个规范其实还可以再严格一些,那就是规定:
如果一个类实现了Serializable接口,就必须手动添加一个private static final long serialVersionUID变量,并且设置初始值。
4.3 为什么要明确定一个serialVersionUID
如果我们没有在类中明确的定义一个serialVersionUID的话,看看会发生什么。
尝试修改上面的demo代码,先使用以下类定义一个对象,该类中不定义serialVersionUID,将其写入文件。
class User1 implements Serializable {
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
然后我们修改User1类,向其中增加一个属性。在尝试将其从文件中读取出来,并进行反序列化。
class User1 implements Serializable {
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
执行结果:
java.io.InvalidClassException: com.hollis.User1; local class incompatible: stream classdesc serialVersionUID = -2986778152837257883, local class serialVersionUID = 7961728318907695402
同样,抛出了InvalidClassException,并且指出两个serialVersionUID不同,分别是-2986778152837257883和7961728318907695402。
从这里可以看出,系统自己添加了一个serialVersionUID。
所以,一旦类实现了Serializable,就建议明确的定义一个serialVersionUID。不然在修改类的时候,就会发生异常。
serialVersionUID有两种显示的生成方式: 一是默认的1L,比如:private static final long serialVersionUID = 1L; 二是根据类名、接口名、成员方法及属性等来生成一个64位的哈希字段,比如: private static final long serialVersionUID = xxxxL;
后面这种方式,可以借助IDE生成,后面会介绍。
4.4 原理
知其然,要知其所以然,我们再来看看源码,分析一下为什么serialVersionUID改变的时候会抛异常?在没有明确定义的情况下,默认的serialVersionUID是怎么来的?
为了简化代码量,反序列化的调用链如下: ObjectInputStream.readObject -> readObject0 -> readOrdinaryObject -> readClassDesc -> readNonProxyDesc -> ObjectStreamClass.initNonProxy
在initNonProxy中 ,关键代码如下:
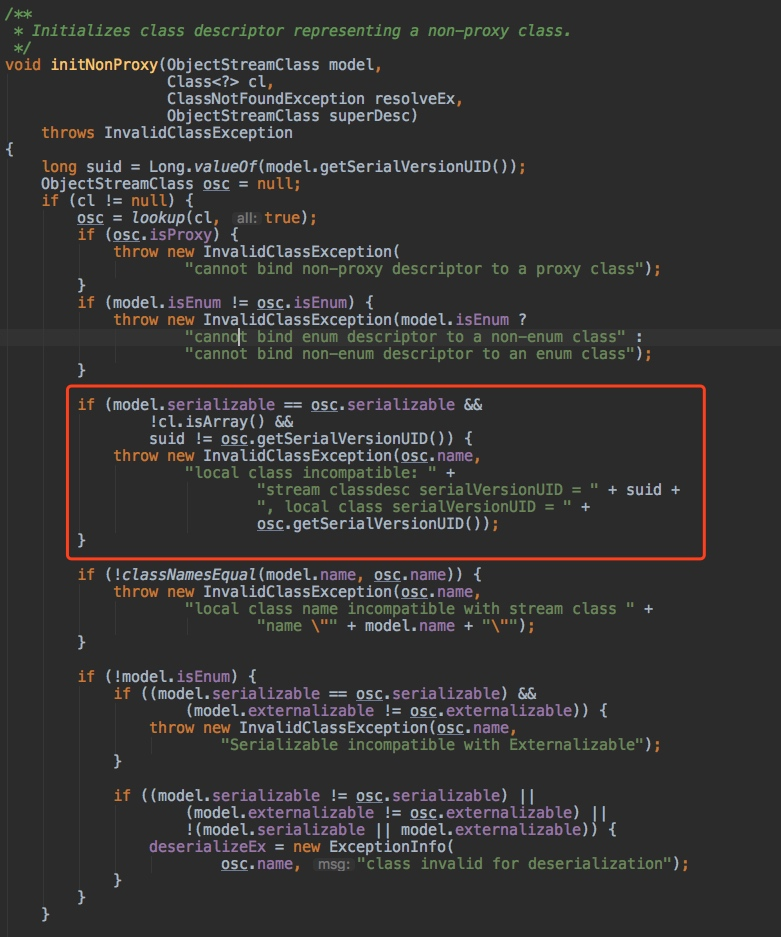
在反序列化过程中,对serialVersionUID做了比较,如果发现不相等,则直接抛出异常。
深入看一下getSerialVersionUID方法:
public long getSerialVersionUID() {
// REMIND: synchronize instead of relying on volatile?
if (suid == null) {
suid = AccessController.doPrivileged(
new PrivilegedAction<Long>() {
public Long run() {
return computeDefaultSUID(cl);
}
}
);
}
return suid.longValue();
}
在没有定义serialVersionUID的时候,会调用computeDefaultSUID 方法,生成一个默认的serialVersionUID。
这也就找到了以上两个问题的根源,其实是代码中做了严格的校验。
4.5 IDEA提示
为了确保我们不会忘记定义serialVersionUID,可以调节一下Intellij IDEA的配置,在实现Serializable接口后,如果没定义serialVersionUID的话,IDEA(eclipse一样)会进行提示:

并且可以一键生成一个:
当然,这个配置并不是默认生效的,需要手动到IDEA中设置一下:
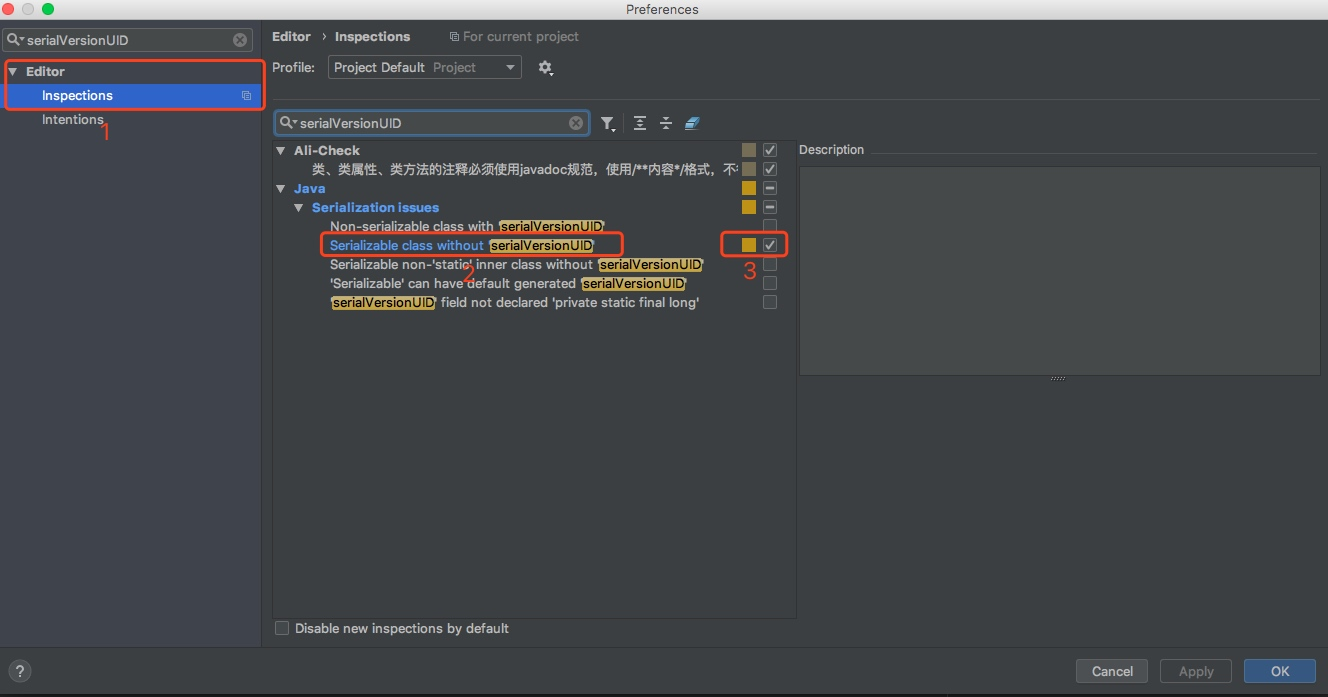
在图中标号3的地方(Serializable class without serialVersionUID的配置),打上勾,保存即可。
4.6 小结
serialVersionUID是用来验证版本一致性的。所以在做兼容性升级的时候,不要改变类中serialVersionUID的值。
如果一个类实现了Serializable接口,一定要记得定义serialVersionUID,否则会发生异常。可以在IDE中通过设置,让他帮忙提示,并且可以一键快速生成一个serialVersionUID。
之所以会发生异常,是因为反序列化过程中做了校验,并且如果没有明确定义的话,会根据类的属性自动生成一个。
5、序列化如何破坏单例模式
5.1 单例模式
单例模式,是设计模式中最简单的一种。通过单例模式可以保证系统中一个类只有一个实例而且该实例易于外界访问,从而方便对实例个数的控制并节约系统资源。如果希望在系统中某个类的对象只能存在一个,单例模式是最好的解决方案。关于单例模式的使用方式,可以阅读单例模式的七种写法
很多人都知道使用反射可以破坏单例模式,除了反射以外,使用序列化与反序列化也同样会破坏单例。
5.2 序列化对单例的破坏
首先来写一个单例的类:
code 1:
package com.hollis;
import java.io.Serializable;
/**
* Created by hollis on 16/2/5.
* 使用双重校验锁方式实现单例
*/
public class Singleton implements Serializable{
private volatile static Singleton singleton;
private Singleton (){
}
public static Singleton getSingleton() {
if (singleton == null) {
synchronized (Singleton.class) {
if (singleton == null) {
singleton = new Singleton();
}
}
}
return singleton;
}
}
接下来是一个测试类:
code 2:
package com.hollis;
import java.io.*;
/**
* Created by hollis on 16/2/5.
*/
public class SerializableDemo1 {
//为了便于理解,忽略关闭流操作及删除文件操作。真正编码时千万不要忘记
//Exception直接抛出
public static void main(String[] args) throws IOException, ClassNotFoundException {
//Write Obj to file
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("tempFile"));
oos.writeObject(Singleton.getSingleton());
//Read Obj from file
File file = new File("tempFile");
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(file));
Singleton newInstance = (Singleton) ois.readObject();
//判断是否是同一个对象
System.out.println(newInstance == Singleton.getSingleton());
}
}
输出结果为false,说明:
- 通过对Singleton的序列化与反序列化得到的对象是一个新的对象,这就破坏了Singleton的单例性。
5.3 ObjectInputStream
对象的序列化过程通过ObjectOutputStream和ObjectInputputStream来实现的,那么带着刚刚的问题,分析一下ObjectInputputStream 的readObject 方法执行情况到底是怎样的。
为了节省篇幅,这里给出ObjectInputStream的readObject的调用栈:
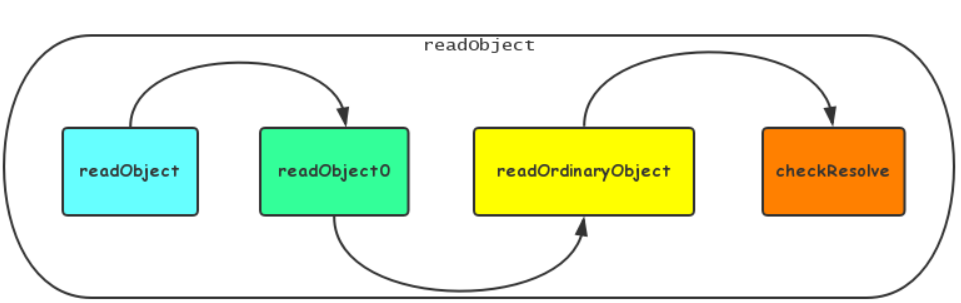
这里看一下重点代码,readOrdinaryObject方法的代码片段:
code 3
private Object readOrdinaryObject(Boolean unshared)
throws IOException
{
//此处省略部分代码
Object obj;
try {
obj = desc.isInstantiable() ? desc.newInstance() : null;
}
catch (Exception ex) {
throw (IOException) new InvalidClassException(
desc.forClass().getName(),
"unable to create instance").initCause(ex);
}
//此处省略部分代码
if (obj != null &&
handles.lookupException(passHandle) == null &&
desc.hasReadResolveMethod())
{
Object rep = desc.invokeReadResolve(obj);
if (unshared && rep.getClass().isArray()) {
rep = cloneArray(rep);
}
if (rep != obj) {
handles.setObject(passHandle, obj = rep);
}
}
return obj;
}
code 3 中主要贴出两部分代码。先分析第一部分:
code 3.1:
Object obj;
try {
obj = desc.isInstantiable() ? desc.newInstance() : null;
}
catch (Exception ex) {
throw (IOException) new InvalidClassException(desc.forClass().getName(),"unable to create instance").initCause(ex);
}
这里创建的这个obj对象,就是本方法要返回的对象,也可以暂时理解为是ObjectInputStream的readObject返回的对象。
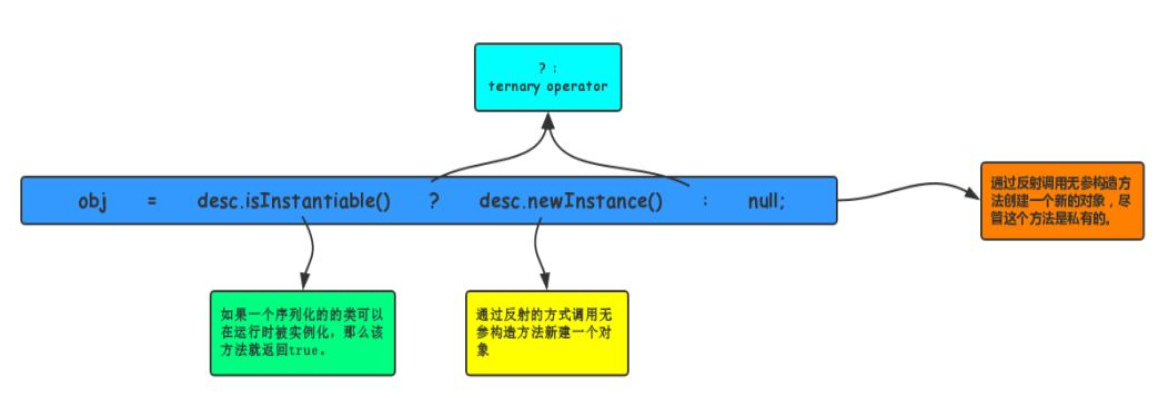
isInstantiable:
- 如果一个serializable/externalizable的类可以在运行时被实例化,那么该方法就返回true。
desc.newInstance:
- 该方法通过反射的方式调用无参构造方法新建一个对象。
所以。到目前为止,也就可以解释,为什么序列化可以破坏单例了?
答:序列化会通过反射调用无参数的构造方法创建一个新的对象。
5.4 防止序列化破坏单例模式
只要在Singleton类中定义readResolve就可以解决该问题:
code 4:
package com.hollis;
import java.io.Serializable;
/**
* Created by hollis on 16/2/5.
* 使用双重校验锁方式实现单例
*/
public class Singleton implements Serializable{
private volatile static Singleton singleton;
private Singleton (){
}
public static Singleton getSingleton() {
if (singleton == null) {
synchronized (Singleton.class) {
if (singleton == null) {
singleton = new Singleton();
}
}
}
return singleton;
}
private Object readResolve() {
return singleton;
}
}
还是运行以下测试类:
package com.hollis;
import java.io.*;
/**
* Created by hollis on 16/2/5.
*/
public class SerializableDemo1 {
//为了便于理解,忽略关闭流操作及删除文件操作。真正编码时千万不要忘记
//Exception直接抛出
public static void main(String[] args) throws IOException, ClassNotFoundException {
//Write Obj to file
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("tempFile"));
oos.writeObject(Singleton.getSingleton());
//Read Obj from file
File file = new File("tempFile");
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(file));
Singleton newInstance = (Singleton) ois.readObject();
//判断是否是同一个对象
System.out.println(newInstance == Singleton.getSingleton());
}
}
本次输出结果为true。具体原理,我们回过头继续分析code 3中的第二段代码:
code 3.2
if (obj != null &&
handles.lookupException(passHandle) == null &&
desc.hasReadResolveMethod())
{
Object rep = desc.invokeReadResolve(obj);
if (unshared && rep.getClass().isArray()) {
rep = cloneArray(rep);
}
if (rep != obj) {
handles.setObject(passHandle, obj = rep);
}
}
hasReadResolveMethod:
- 如果实现了serializable 或者 externalizable接口的类中包含readResolve则返回true
invokeReadResolve:
- 通过反射的方式调用要被反序列化的类的readResolve方法。
所以,原理也就清楚了,主要在Singleton中定义readResolve方法,并在该方法中指定要返回的对象的生成策略,就可以防止单例被破坏。
5.5 小结
在涉及到序列化的场景时,要格外注意他对单例的破坏。
6、使用序列化实现深拷贝
6.1 原理
原理就是先把对象序列化成流,再将流反序列化成对象,这样得到的对象就一定是新对象啦。
6.2 方式
序列化的方式有很多,比如我们可以使用各种JSON工具把对象序列化成JSON字符串,再将字符串反序列化成对象。如果使用Fastjson,则代码如下:
User newUser = JSON.parseObject(JSON.toJSONString(user),User.class);
这样也可以实现深拷贝。
除此之外,还可以使用Apache Commons Lang中提供得SerializationUtils工具实现深拷贝。
我们需要修改上面的User和Address类,使他们实现Serializable接口,否则无法实现序列化:
Class User implements Serializable
Class Address implements Serializable
同样可以实现深拷贝:
User newUser = (User)SerializationUtils.clone(user);
7、Apache-Commons-Collections的反序列化漏洞
详见:Apache-Commons-Collections的反序列化漏洞
8、fastjson的反序列化漏洞
8.1 背景
fastjson大家一定都不陌生,这是阿里巴巴的开源一个JSON解析库,通常被用于将Java Bean和JSON 字符串之间进行转换。
前段时间,fastjson被爆出过多次存在漏洞,这其实和fastjson中的一个AutoType特性有关。
从2019年7月份发布的v1.2.59一直到2020年6月份发布的 v1.2.71 ,每个版本的升级中都有关于AutoType的升级。
下面是fastjson的官方releaseNotes 中,几次关于AutoType的重要升级:
- 1.2.59发布,增强AutoType打开时的安全性 fastjson
- 1.2.60发布,增加了AutoType黑名单,修复拒绝服务安全问题 fastjson
- 1.2.61发布,增加AutoType安全黑名单 fastjson
- 1.2.62发布,增加AutoType黑名单、增强日期反序列化和JSONPath fastjson
- 1.2.66发布,Bug修复安全加固,并且做安全加固,补充了AutoType黑名单 fastjson
- 1.2.67发布,Bug修复安全加固,补充了AutoType黑名单 fastjson
- 1.2.68发布,支持GEOJSON,补充了AutoType黑名单。(引入一个safeMode的配置,配置safeMode后,无论白名单和黑名单,都不支持autoType。) fastjson
- 1.2.69发布,修复新发现高危AutoType开关绕过安全漏洞,补充了AutoType黑名单 fastjson
- 1.2.70发布,提升兼容性,补充了AutoType黑名单
甚至在fastjson的开源库中,有一个Issue是建议作者提供不带autoType的版本:
那么,什么是AutoType?为什么fastjson要引入AutoType?为什么AutoType会导致安全漏洞呢?本文就来深入分析一下。AutoType 何方神圣?
8.2 AutoType 是何方神圣
fastjson的主要功能就是将Java Bean序列化成JSON字符串,这样得到字符串之后就可以通过数据库等方式进行持久化了。
但是,fastjson在序列化以及反序列化的过程中并没有使用Java自带的序列化机制(https://www.hollischuang.com/archives/1140),而是自定义了一套机制。
其实,对于JSON框架来说,想要把一个Java对象转换成字符串,可以有两种选择:
- 基于属性
- 基于setter/getter
而我们所常用的JSON序列化框架中,FastJson和jackson在把对象序列化成json字符串的时候,是通过遍历出该类中的所有getter方法进行的。Gson并不是这么做的,他是通过反射遍历该类中的所有属性,并把其值序列化成json。
假设我们有以下一个Java类:
class Store {
private String name;
private Fruit fruit;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Fruit getFruit() {
return fruit;
}
public void setFruit(Fruit fruit) {
this.fruit = fruit;
}
}
interface Fruit {
}
class Apple implements Fruit {
private BigDecimal price;
//省略 setter/getter、toString等
}
当我们要对他进行序列化的时候,fastjson会扫描其中的getter方法,即找到getName和getFruit,这时候就会将name和fruit两个字段的值序列化到JSON字符串中。
那么问题来了,我们上面的定义的Fruit只是一个接口,序列化的时候fastjson能够把属性值正确序列化出来吗?如果可以的话,那么反序列化的时候,fastjson会把这个fruit反序列化成什么类型呢?
我们尝试着验证一下,基于(fastjson v 1.2.68):
Store store = new Store();
store.setName("Hollis");
Apple apple = new Apple();
apple.setPrice(new BigDecimal(0.5));
store.setFruit(apple);
String jsonString = JSON.toJSONString(store);
System.out.println("toJSONString : " + jsonString);
以上代码比较简单,我们创建了一个store,为他指定了名称,并且创建了一个Fruit的子类型Apple,然后将这个store使用JSON.toJSONString进行序列化,可以得到以下JSON内容:
toJSONString : {"fruit":{"price":0.5},"name":"Hollis"}
那么,这个fruit的类型到底是什么呢,能否反序列化成Apple呢?我们再来执行以下代码:
Store newStore = JSON.parseObject(jsonString, Store.class);
System.out.println("parseObject : " + newStore);
Apple newApple = (Apple)newStore.getFruit();
System.out.println("getFruit : " + newApple);
执行结果如下:
toJSONString : {"fruit":{"price":0.5},"name":"Hollis"}
parseObject : Store{name='Hollis', fruit={}}
Exception in thread "main" java.lang.ClassCastException: com.hollis.lab.fastjson.test.$Proxy0 cannot be cast to com.hollis.lab.fastjson.test.Apple
at com.hollis.lab.fastjson.test.FastJsonTest.main(FastJsonTest.java:26)
可以看到,在将store反序列化之后,我们尝试将Fruit转换成Apple,但是抛出了异常,尝试直接转换成Fruit则不会报错,如:
Fruit newFruit = newStore.getFruit();
System.out.println("getFruit : " + newFruit);
以上现象,我们知道,当一个类中包含了一个接口(或抽象类)的时候,在使用fastjson进行序列化的时候,会将子类型抹去,只保留接口(抽象类)的类型,使得反序列化时无法拿到原始类型。
那么有什么办法解决这个问题呢,fastjson引入了AutoType,即在序列化的时候,把原始类型记录下来。
使用方法是通过SerializerFeature.WriteClassName进行标记,即将上述代码中的
String jsonString = JSON.toJSONString(store);
修改成:
String jsonString = JSON.toJSONString(store,SerializerFeature.WriteClassName);
即可,以上代码,输出结果如下:
System.out.println("toJSONString : " + jsonString);
{
"@type":"com.hollis.lab.fastjson.test.Store",
"fruit":{
"@type":"com.hollis.lab.fastjson.test.Apple",
"price":0.5
},
"name":"Hollis"
}
可以看到,使用SerializerFeature.WriteClassName进行标记后,JSON字符串中多出了一个@type字段,标注了类对应的原始类型,方便在反序列化的时候定位到具体类型。
如上,将序列化后的字符串在反序列化,既可以顺利的拿到一个Apple类型,整体输出内容:
toJSONString : {"@type":"com.hollis.lab.fastjson.test.Store","fruit":{"@type":"com.hollis.lab.fastjson.test.Apple","price":0.5},"name":"Hollis"}
parseObject : Store{name='Hollis', fruit=Apple{price=0.5}}
getFruit : Apple{price=0.5}
这就是AutoType,以及fastjson中引入AutoType的原因。
但是,也正是这个特性,因为在功能设计之初在安全方面考虑的不够周全,也给后续fastjson使用者带来了无尽的痛苦。
8.3 AutoType 何错之有
绕过checkAutotype,攻击者与fastjson的博弈
在fastjson v1.2.41 之前,在checkAutotype的代码中,会先进行黑白名单的过滤,如果要反序列化的类不在黑白名单中,那么才会对目标类进行反序列化。
但是在加载的过程中,fastjson有一段特殊的处理,那就是在具体加载类的时候会去掉className前后的L和;,形如Lcom.lang.Thread;
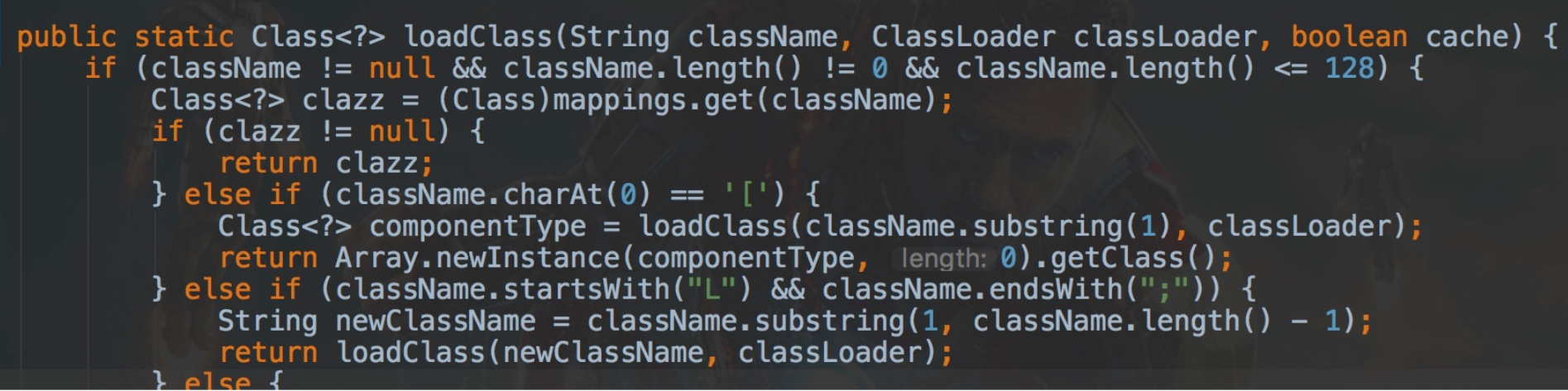
而黑白名单又是通过startWith检测的,那么黑客只要在自己想要使用的攻击类库前后加上L和;就可以绕过黑白名单的检查了,也不耽误被fastjson正常加载。
如Lcom.sun.rowset.JdbcRowSetImpl;,会先通过白名单校验,然后fastjson在加载类的时候会去掉前后的L和;,变成了com.sun.rowset.JdbcRowSetImpl。
为了避免被攻击,在之后的 v1.2.42版本中,在进行黑白名单检测的时候,fastjson先判断目标类的类名的前后是不是L和;,如果是的话,就截取掉前后的L和;再进行黑白名单的校验。
看似解决了问题,但是黑客发现了这个规则之后,就在攻击时在目标类前后双写LL和;;,这样再被截取之后还是可以绕过检测。如LLcom.sun.rowset.JdbcRowSetImpl;;
魔高一尺,道高一丈。在 v1.2.43中,fastjson这次在黑白名单判断之前,增加了一个是否以LL开头的判断,如果目标类以LL开头,那么就直接抛异常,于是就又短暂的修复了这个漏洞。
黑客在L和;这里走不通了,于是想办法从其他地方下手,因为fastjson在加载类的时候,不只对L和;这样的类进行特殊处理,还对[特殊处理了。
同样的攻击手段,在目标类前面添加[,v1.2.43以前的所有版本又沦陷了。
于是,在 v1.2.44版本中,fastjson的作者做了更加严格的要求,只要目标类以[开头或者以;结尾,都直接抛异常。也就解决了 v1.2.43及历史版本中发现的bug。
在之后的几个版本中,黑客的主要的攻击方式就是绕过黑名单了,而fastjson也在不断的完善自己的黑名单。
autoType不开启也能被攻击?
但是好景不长,在升级到 v1.2.47 版本时,黑客再次找到了办法来攻击。而且这个攻击只有在autoType关闭的时候才生效。
是不是很奇怪,autoType不开启反而会被攻击。
因为在fastjson中有一个全局缓存,在类加载的时候,如果autotype没开启,会先尝试从缓存中获取类,如果缓存中有,则直接返回。黑客正是利用这里机制进行了攻击。
黑客先想办法把一个类加到缓存中,然后再次执行的时候就可以绕过黑白名单检测了,多么聪明的手段。
首先想要把一个黑名单中的类加到缓存中,需要使用一个不在黑名单中的类,这个类就是java.lang.Class。
java.lang.Class类对应的deserializer为MiscCodec,反序列化时会取json串中的val值并加载这个val对应的类。如果fastjson cache为true,就会缓存这个val对应的class到全局缓存中- 如果再次加载val名称的类,并且autotype没开启,下一步就是会尝试从全局缓存中获取这个class,进而进行攻击。
- 所以,黑客只需要把攻击类伪装以下就行了,如下格式:
{"@type": "java.lang.Class","val": "com.sun.rowset.JdbcRowSetImpl"}
于是在 v1.2.48中,fastjson修复了这个bug,在MiscCodec中,处理Class类的地方,设置了fastjson cache为false,这样攻击类就不会被缓存了,也就不会被获取到了。
在之后的多个版本中,黑客与fastjson又继续一直都在绕过黑名单、添加黑名单中进行周旋。
直到后来,黑客在 v1.2.68之前的版本中又发现了一个新的漏洞利用方式。
利用异常进行攻击
在fastjson中, 如果,@type 指定的类为 Throwable 的子类,那对应的反序列化处理类就会使用到 ThrowableDeserializer
而在ThrowableDeserializer#deserialze的方法中,当有一个字段的key也是 @type时,就会把这个 value 当做类名,然后进行一次 checkAutoType 检测。
并且指定了expectClass为Throwable.class,但是在checkAutoType中,有这样一约定,那就是如果指定了expectClass ,那么也会通过校验。

因为fastjson在反序列化的时候会尝试执行里面的getter方法,而Exception类中都有一个getMessage方法。
黑客只需要自定义一个异常,并且重写其getMessage就达到了攻击的目的。
这个漏洞就是6月份全网疯传的那个"严重漏洞",使得很多开发者不得不升级到新版本。
这个漏洞在 v1.2.69中被修复,主要修复方式是对于需要过滤掉的expectClass进行了修改,新增了4个新的类,并且将原来的Class类型的判断修改为hash的判断。
其实,根据fastjson的官方文档介绍,即使不升级到新版,在v1.2.68中也可以规避掉这个问题,那就是使用safeMode。
8.4 AutoType 安全模式
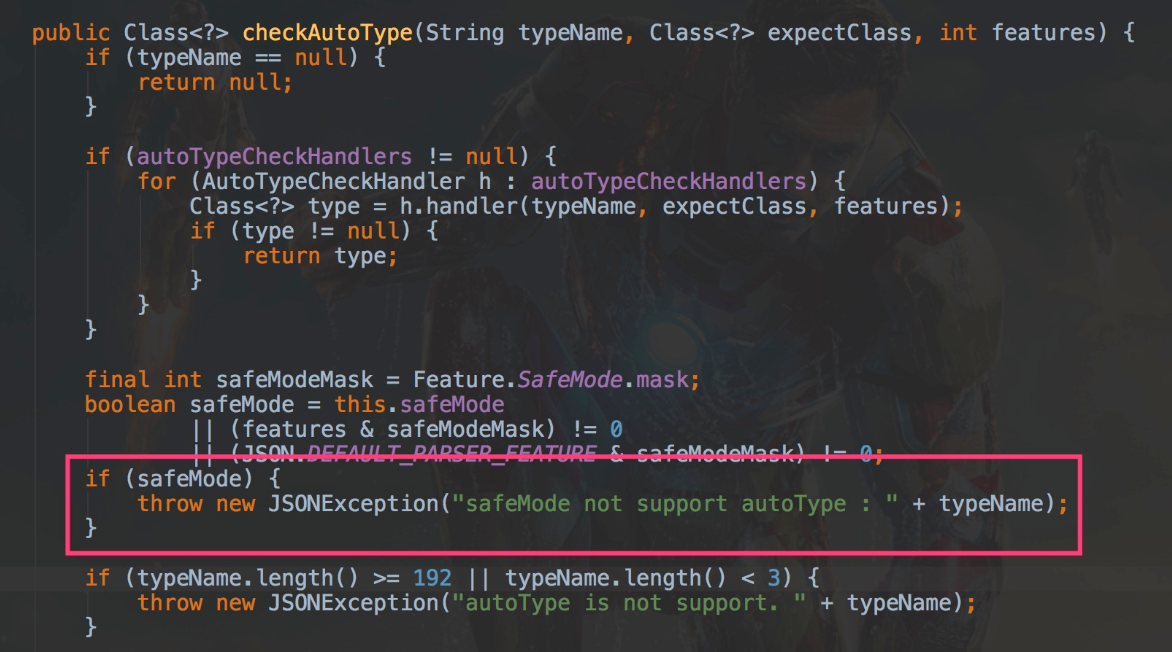
可以看到,这些漏洞的利用几乎都是围绕AutoType来的,于是,在 v1.2.68版本中,引入了safeMode,配置safeMode后,无论白名单和黑名单,都不支持autoType,可一定程度上缓解反序列化Gadgets类变种攻击。
设置了safeMode后,@type 字段不再生效,即当解析形如{"@type": "com.java.class"}的JSON串时,将不再反序列化出对应的类。
开启safeMode方式如下:
ParserConfig.getGlobalInstance().setSafeMode(true);
如在本文的最开始的代码示例中,使用以上代码开启safeMode模式,执行代码,会得到以下异常:
Exception in thread "main" com.alibaba.fastjson.JSONException: safeMode not support autoType : com.hollis.lab.fastjson.test.Apple
at com.alibaba.fastjson.parser.ParserConfig.checkAutoType(ParserConfig.java:1244)
但是值得注意的是,使用这个功能,fastjson会直接禁用autoType功能,即在checkAutoType方法中,直接抛出一个异常。
8.5 后话
目前fastjson已经发布到了 v1.2.72版本,历史版本中存在的已知问题在新版本中均已修复。
开发者可以将自己项目中使用的fastjson升级到最新版,并且如果代码中不需要用到AutoType的话,可以考虑使用safeMode,但是要评估下对历史代码的影响。
因为fastjson自己定义了序列化工具类,并且使用asm技术避免反射、使用缓存、并且做了很多算法优化等方式,大大提升了序列化及反序列化的效率。
之前有网友对比过:
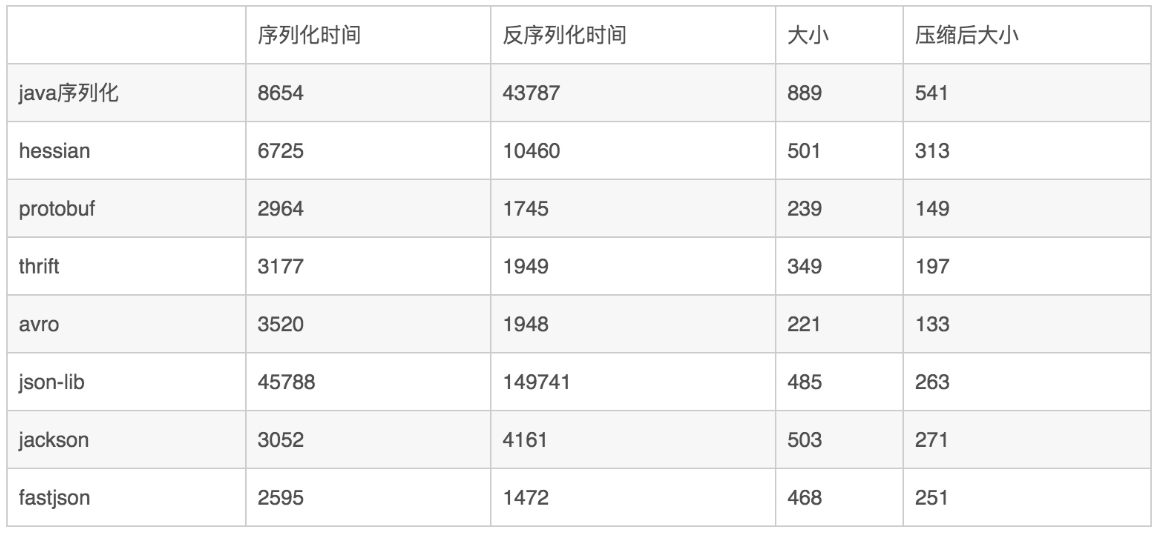
当然,快的同时也带来了一些安全性问题,这是不可否认的。
参考资料:
- https://github.com/alibaba/fastjson/releases
- https://github.com/alibaba/fastjson/wiki/security_update_20200601
- https://paper.seebug.org/1192/
- https://mp.weixin.qq.com/s/EXnXCy5NoGIgpFjRGfL3wQ
- http://www.lmxspace.com/2019/06/29/FastJson-反序列化学习
9、JavaBean属性名对序列化的影响
建议读者使用success而不是isSuccess这种形式。这样,该类中的成员变量是success,getter方法是isSuccess,这是完全符合JavaBeans规范的。无论那种序列化框架,执行结果都一样。